Working with the OpenAI API in Python
Introduction
- Notebook Author: Trenton McKinney
- GitHub: 2024-01-29_working_with_the_openai_api.ipynb
- Course: Working with the OpenAI API in Python
- This notebook was created as a reproducible reference.
- In you find the content beneficial, consider a DataCamp Subscription.
Course Description
Over recent years, OpenAI has emerged as a market leader in creating AI models, such as GPT-4, and releasing them to the wider community in applications like ChatGPT. These models can transform not only the way you work but also the products and services that businesses provide to customers. To begin extracting business value from OpenAI’s models, you’ll need to learn to work with their Application Programming Interface, or API. In this course, you’ll gain hands-on experience working with the OpenAI API in Python, and will explore the wide range of functionality that the API provides. By the end of the course, you’ll have the skills and knowledge needed to leverage the power of the OpenAI API to develop solutions to real-world problems.
- Your first API request!
- Write Python code to interact with the OpenAI API
- Creation of an API key and account setup
- Budget considerations for API usage and rate limits.
- The OpenAI developer ecosystem
- Overview of OpenAI’s diverse models
- Focus on text-based models and introduction to audio capabilities with the Whisper model
- Features include Images, Chat, Embeddings, Audio, Completion, Fine-tuning, and Moderation.
- OpenAI’s Text and Chat Capabilities
- Generating and transforming text content
- Classification tasks like categorization and sentiment analysis
- Creating AI-powered chatbots.
- Text completions
- Deep dive into text and chat functionalities
- Beyond answering questions: exploring text completion works.
- Understanding tokens
- Tokens as a unit for language models to interpret text.
- Find and replace
- Utilizing models for text prompt transformation.
- Text summarization
- Summarizing text for business applications.
Imports
1
2
from openai import OpenAI
from configparser import ConfigParser
Load the API Key
1
2
3
4
5
6
# create an instance of the ConfigParser class
config = ConfigParser()
# read the API key from a config.ini
config.read('../config_api.ini')
api_key = config['openai']['key']
Create an Instance of the OpenAI Class with the API Key
1
client = OpenAI(api_key=api_key)
Introduction to the OpenAI API
Harness the power of AI from OpenAI’s models by creating requests to their API with just a few lines of code. Discover the wide range of capabilities available via the OpenAI API. Learn about the best practices for managing API usage across the business by utilizing API organizations.
What is the OpenAI API
What is the OpenAI API?: Welcome to this course! I’m James, and I’ll be your host as we explore the artificial intelligence functionality available via the OpenAI API!
Coming up…: In this course, you’ll learn how to use the AI models available through the OpenAI API to solve a wide range of real-world tasks. To do this, we’ll be using Python code throughout the course, and expect familiarity with a few Python programming topics like subsetting lists and dictionaries, control flow, and looping. However, no experience with AI or machine learning is required. With that, let’s dive right in!
- Course goals
- Use the OpenAI API to access AI models
- Use those models to solve various tasks
- Use Python code to do this!
- Course goals
- Expected knowledge
- Subsetting Python lists and dictionaries
- Control flow:
if,elif,else - Loops:
for,while
- Not expected to know
- AI or machine learning
- OpenAI, ChatGPT, and the OpenAI API: OpenAI is a company that researches and develops artificial intelligence systems. One of their most famous developments is ChatGPT, which is an application that allows users to communicate with an AI-powered chatbot to ask questions, perform tasks, or generate content. The OpenAI API allows individuals or organizations to access and customize any of the models developed and released by OpenAI. If OpenAI was a car manufacturer, ChatGPT would be their shiny new sports car that people can walk into a dealership and test drive. The OpenAI API would be like the system customers could use to customize and order any car from the manufacturer’s catalog.
- OpenAI: AI R&D company
- ChatGPT: AI application
- OpenAI API: Interface for accessing OpenAI models
What is an API?: So what actually is an API? API stands for Application Programming Interface, and they act as a messenger between software applications, taking a request to a system and receiving a response containing data or services. An API is like a waiter in a restaurant; they take our order, or request, communicate it to the kitchen—the system providing the service—and finally, deliver the food, or response from the system, back to our table. Many applications interact using APIs; for example, a mobile weather app may send our location to an API and request the local forecast, which gets returned to our phones.
The OpenAI API: We can similarly write code to interact with the OpenAI API and request the use of one of their models. Our request, in this case, will specify which model we want, the data that we want the model to use, and any other parameters to customize the model’s behavior. The response, containing the model result, is then returned to us.
- API vs. web interface: Some of OpenAI’s models, such as ChatGPT, can be used from the web browser, so what are the benefits of accessing them via the API? If we’re looking to streamline our individual workflows using AI, then a low-setup web browser experience is likely sufficient for our purposes. However, if we’re looking to begin integrating AI into our products, customer experiences, or business processes, we’ll need the flexibility of working with the API using a programming language.
- API
- Provides flexibility for integrating AI into products, experiences, and processes
- Interact via programming language
- Web Interface
- Very little setup
- Sufficient for streamlining individual’s workflows
- API
- Why the OpenAI API?: The beauty of making these models available via an API is that software engineers, developers, or anyone else wanting to integrate AI into products and services, can now access and implement these models without needing a background in data science or machine learning.
- Accessibility to AI
- Don’t require data or ML experience
- Building AI applications: The OpenAI API has enabled the development of powerful new features, that before, would have required enormous computational resources and data. In the example shown from DataCamp workspace, we developed a feature where users can write or fix code by providing an instruction—all built on the OpenAI API. AI-powered products and services can provide much greater personalization to customers, so experiences can be tailored to an individual’s needs and preferences.
Applications built on the OpenAI API
Software applications, web browser experiences, and even whole products are being built on top of the OpenAI API. In this exercise, you’ll be able to explore an application built on top of the OpenAI API: DataCamp’s own version of ChatGPT!
The text you type into the interface will be sent as a request to the OpenAI API and the response will be delivered and unpacked directly back to you.
Using the ChatGPT interface, answer the following question: In what year was OpenAI founded?
Answer:
- 2015
There are countless other applications out there that harness the power of AI to solve complex problems and streamline the way you work.
Understanding the OpenAI space
There’s no better time to be learning about AI! Advancements in artificial intelligence has meant that AI-powered product features and tools are within reaching distance for more individuals and organizations than ever before.
In this exercise, you’ll test your understanding of some of the major players in the AI space: OpenAI, ChatGPT, and the OpenAI API.
Answer:
OpenAI
- Organization for researching and developing AI
- Developed ChatGPT
ChatGPT
- Users have conversations using plain text
- AI application for generating content
OpenAI API
- Users can decide which model to use and customize its behavior
- Users create API requests to communicate model usage
- Interface for accessing and customizing AI models
Now that you understand what the OpenAI API is and how powerful and accessible the functionality it provides is, head on over to the next video to learn how to leverage it with Python code!
Making requests to the OpenAI API
Making requests to the OpenAI API: Welcome back! In this video, you’ll learn to make your very first request to the OpenAI API!
APIs recap…: Recall that we can request the use of a model from OpenAI by making a request to their API.
- API endpoints: Depending on the model or services required, APIs have different access points for users. These access points are called endpoints. Endpoints are a lot like doors in a hospital. Depending on the treatment required, patients use different doors to reach different departments, and likewise, users can use different API endpoints to request different services.
- Endpoints → API access point designed for specific interactions
- API authentication: Endpoints, like many hospital departments, may also require authentication before accessing services. API authentication is usually in the form of providing a unique key containing a random assortment of characters.
- Authentication → Controls on access to API endpoint services (often unique key)
- API usage costs: It’s important to note that many APIs, including the OpenAI API, have costs associated with using their services. For OpenAI, these costs are dependent on the model requested and on the size of the model input and output.
- OpenAI pricing
- For OpenAI API:
- Larger inputs + outputs = Greater cost
- API documentation: A crucial part of working with APIs is navigating API documentation, which provides details on which endpoints to use, their functionality, and how to set up authentication. Throughout the course, we’ll provide these API details, but we also recommend checking out OpenAI’s excellent API documentation.
Creating an OpenAI API key: Usage of OpenAI’s API requires authentication, so to use the API and complete the exercises in this course, you’ll need to set up an account. OpenAI often provides free trial credit to new users, which will be more than sufficient for completing this course; however, for some countries, you may need to add a small amount of credit. Creating an OpenAI API key: Then, for authentication, you’ll need to create a secret key and copy it. DataCamp doesn’t store any API keys used in this course, so you can copy it directly into the exercises. Let’s make our first API request!
- Making a request: There are several ways to interact with an API, but in this course, we’ll use OpenAI’s own Python library, which abstracts away a lot of the complexity of working with an API. We start by importing the OpenAI class from openai, which we’ll use to instantiate a Python API client. The client configures the environment for communicating with the API. Within this function, we specify our API key, which is used to authenticate requests. Now for the API request code. We’ll start by creating a request to the completions endpoint, which is used for completing a text prompt, by calling the create method on client.completions. Inside this method, we specify the model and the prompt to send to it. We’ll discuss prompts in greater detail later in the course. Let’s take a look at the API response.
1
2
3
4
5
6
from openai import OpenAI
client = OpenAI(api_key="ENTER YOUR KEY HERE")
response = client.completions.create(model="gpt-3.5-turbo-instruct", prompt="What is the OpenAI API?")
print(response)
- The response: Here’s the response. There’s a lot of information in the output, so we’ll add some spacing to make it more readable. The response from the API is a Completion object, which has various attributes for accessing the different information it contains. It has an id attribute, and choices, created, model, and other attributes below. We can see that the text response is located under the .choices attribute,
1
2
3
4
5
6
7
Completion(id='cmpl-8S0D6VZBpM8Vy0fZf6atE71b1Zdvm',
choices=[CompletionChoice(finish_reason='length', index=0, logprobs=None, text='\n\nThe OpenAI API is an application programming interface provided by OpenAI, a')],
created=1701684684,
model='gpt-3.5-turbo-instruct',
object='text_completion',
system_fingerprint=None,
usage=CompletionUsage(completion_tokens=16, prompt_tokens=7, total_tokens=23))
- Interpreting the response: so we’ll start by accessing that. Attributes are accessed using a dot, then the name of the attribute. We’ve gotten much closer to the text. Notice from the square brackets at the beginning and end, that this is actually a list with a single element. Let’s extract the first element to dig further. Ok - now we’re left with a CompletionChoice object, which has its own set of attributes. Our text response is located underneath its .text attribute, which we can chain to our existing code. There we have it—our text response as a string! We started off with a complex object, but by taking it one attribute at a time, we were able to get to the result.
1
2
3
4
print(response.choices)
[out]:
[CompletionChoice(finish_reason='length', index=0, logprobs=None, text='\n\nThe OpenAI API is an application programming interface provided by OpenAI, a')]
1
2
3
4
print(response.choices[0])
[out]:
CompletionChoice(finish_reason='length', index=0, logprobs=None, text='\n\nThe OpenAI API is an application programming interface provided by OpenAI, a')
1
2
3
4
print(response.choices[0].text)
[out]:
The OpenAI API is an application programming interface provided by OpenAI, a
- Converting the response into a dictionary: In some cases, we may wish to work with a dictionary instead. We can convert the response into a dictionary with the .model_dump() method. In dictionary form, the response’s attributes become dictionary keys, but the structure remains the same.
1
2
3
4
5
6
7
8
9
10
11
12
13
print(response.model_dump())
[out]:
{'id': 'cmpl-8S0D6VZBpM8Vy0fZf6atE71b1Zdvm',
'choices': [{'finish_reason': 'length',
'index': 0,
'logprobs': None,
'text': '\n\nThe OpenAI API is an application programming interface provided by OpenAI, a'}],
'created': 1701684684,
'model': 'gpt-3.5-turbo-instruct',
'object': 'text_completion',
'system_fingerprint': None,
'usage': {'completion_tokens': 16, 'prompt_tokens': 7, 'total_tokens': 23}}
Your first API request!
Throughout the course, you’ll write Python code to interact with the OpenAI API. As a first step, you’ll need to create your own API key. API keys used in this course’s exercises will not be stored in any way.
To create a key, you’ll first need to create an OpenAI account by visiting their signup page. Next, navigate to the API keys page to create your secret key.
The button to create a new secret key.
OpenAI sometimes provides free credits for the API, but this can differ depending on geography. You may also need to add debit/credit card details. You’ll need less than $1 credit to complete this course.
Warning: if you send many requests or use lots of tokens in a short period, you may see an openai.error.RateLimitError. If you see this error, please wait a minute for your quota to reset and you should be able to begin sending more requests. Please see OpenAI’s rate limit error support article for more information.
1
2
# create an instance of the OpenAI class
# client = OpenAI(api_key=api_key) # creted at the top of the notebook
1
2
# call the completion endpoint
response = client.completions.create(model='gpt-3.5-turbo-instruct', prompt='Who developed ChatGPT')
1
2
# print the response
print(response.choices[0].text.strip())
1
ChatGPT was developed by OpenAI, a research lab focused on
1
print(response)
1
Completion(id='cmpl-9EQ17xyBCVnQVVYhX96VGIZWnSSAO', choices=[CompletionChoice(finish_reason='length', index=0, logprobs=None, text='\n\nChatGPT was developed by OpenAI, a research lab focused on')], created=1713223629, model='gpt-3.5-turbo-instruct', object='text_completion', system_fingerprint=None, usage=CompletionUsage(completion_tokens=16, prompt_tokens=5, total_tokens=21))
You’ve just taken your very first steps on the road to creating awesome AI-powered applications and experiences. In the next exercise, you’ll practice digging into the JSON response to extract the returned text.
Digging into the response
One of the key skills required to work with APIs is manipulating the response to extract the desired information. In this exercise, you’ll push your Python dictionary and list manipulation skills to the max to extract information from the API response.
You’ve been provided with response, which is a response from the OpenAI API when provided with the prompt, What is the goal of OpenAI?
This response object has been printed for you so you can see and understand its structure. If you’re struggling to picture the structure, view the dictionary form of the response with .model_dump().
1
response.model_dump()
1
2
3
4
5
6
7
8
9
10
{'id': 'cmpl-9EQ17xyBCVnQVVYhX96VGIZWnSSAO',
'choices': [{'finish_reason': 'length',
'index': 0,
'logprobs': None,
'text': '\n\nChatGPT was developed by OpenAI, a research lab focused on'}],
'created': 1713223629,
'model': 'gpt-3.5-turbo-instruct',
'object': 'text_completion',
'system_fingerprint': None,
'usage': {'completion_tokens': 16, 'prompt_tokens': 5, 'total_tokens': 21}}
1
response.model
1
'gpt-3.5-turbo-instruct'
1
response.usage.total_tokens
1
21
1
response.choices[0].text
1
'\n\nChatGPT was developed by OpenAI, a research lab focused on'
Throughout the course, you’ll learn to perform lots of different tasks by making requests to the OpenAI API, and each time, you’ll use similar subsetting to dig into the response and extract the result.
The OpenAI developer ecosystem
- The OpenAI landscape: Despite being renowned for its GPT series of chat models, OpenAI hosts a diverse array of models capable of performing many different tasks. In this course, we’ll be focusing primarily on OpenAI’s text-based models, but later in the course, we’ll also take a look at the audio transcription and translation capabilities of the Whisper model. For now, however, let’s take a closer look at the text capabilities available through the API.
- Images
- Chat
- Embeddings
- Audio
- Completion
- Fine-tuning
- Moderation
- Completions: The Completions endpoint allows users to send a prompt and receive a model-generated response that attempts to complete the prompt in a likely and consistent way. Completions is used for so-called single-turn tasks, as there is a single prompt and response. However, the models available via this endpoint are extremely flexible, and are capable of answering questions, performing classification tasks, determining text sentiment, explaining complex topics, and much more.
- Receive continuation of a prompt
- Single-turn tasks
- Answer questions
- Classification into categories
- Sentiment analysis
- Explain complex topics
- Chat: The Chat endpoint can be used for applications that require multi-turn tasks, including assisting with ideation, customer support questions, personalized tutoring, translating languages, and writing code. Chat models also perform well on single-turn tasks, so many applications are built on top of chat models for flexibility. We’ll cover how to use Chat later in the course.
- Multi-turn conversations
- Ideation
- Customer support assistant
- Personal tutor
- Translate languages
- Write code
- Also performs well on single-turn tasks
- Chat completions → Chapter 2
- Multi-turn conversations
- Moderation: The Moderation endpoint is used to check whether content violates OpenAI’s usage policies, such inciting violence or promoting hate speech. The sensitivity of the model to different types of violations can be customized for specific use cases that may require stricter or more lenient moderation.
- Usage policies
- Overview
- Check content for violations of OpenAI’s usage policies, including:
- Inciting violence
- Hate speech
- Can customize model sensitivity to specific violations
- Organizations: For business use cases with frequent requests to the API, it’s important to manage usage across the business. Setting up an organization for the API allows for better management of access, billing, and usage limits to the API. Users can be part of multiple organizations and attribute requests to specific organizations for billing. To attribute a request to a specific organization, we only need to add one more line of code. Like the API key, the organization ID can be set before the request.
1
2
3
4
from openai import OpenAI
client = OpenAI(api_key="ENTER YOUR KEY HERE", organization = "ENTER ORG ID")
response = client.completions.create(model="gpt-3.5-turbo-instruct", prompt="What is the OpenAI API?")
print(response)
- Rate limits: API rate limits are another key consideration for companies building features on the OpenAI API. Rate limits are a cap on the frequency and size of API requests. They are put in place to ensure fair access to the API, prevent misuse, and also manage the infrastructure that supports the API. For many cases, this may not be an issue, but if a feature is exposed to a large user base, or the requests require generating large bodies of content, they could be at risk of hitting the rate limits.
- Rate Limits
- Cap on frequency and size of API requests
- Organization structure: Much of this risk can be mitigated by, instead of running multiple features under the same organization, having separate organizations for each business unit or product feature, depending on the number of features built on the OpenAI API. In this example, we’ve created separate OpenAI organizations for three different AI-powered features: a customer service chatbot, a content recommendation system, and a video transcript generator. This distributes the requests to reduce the risk of hitting the rate limit. It also removes the single failure point, so an issue to one organization, such as a billing issue, will only result in the failure of a single feature. Product-separated organizations also provide more granular insights into usage and billing.
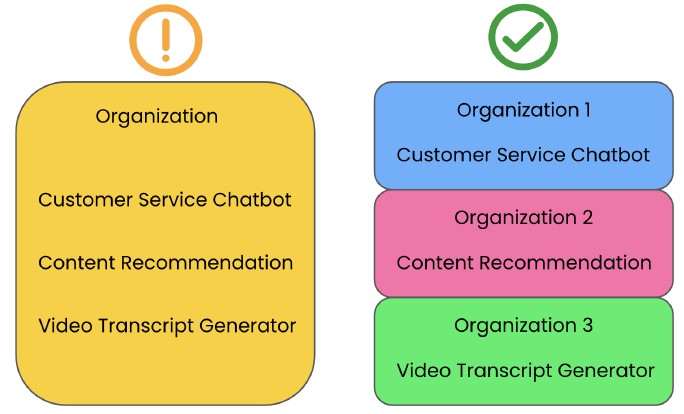
- Distributes requests across organizations
- Reduced likelihood of hitting rate limits
- Removes single failure point
- Issue with one organization doesn’t break all features
- Better usage and billing management
Solving problems with AI solutions
An Online Scientific Journal called Terra Scientia wants to use AI to make their scientific papers more accessible to a wider audience. To do this, they want to develop a feature where users can double-click on words they don’t understand, and an AI model will explain what it means in the context of the article.
To accomplish this, the developers at Terra Scientia want to build the feature on top of the OpenAI API.
Which OpenAI API endpoint(s) could they use to build this feature?
Answer:
- Chat
- Moderation
Evaluating the situation and model capabilities to see if (1) AI can be used to solve the problem, and (2) what the implementation would look like is the crucial starting place for AI feature development.
Structuring organizations
You’ve learned that you can set up organizations to manage API usage and billing. Users can be part of multiple organizations and attribute API requests to a specific organization. It’s best practice to structure organizations such that each business unit or product feature has a separate organization, depending on the number of features the business has built on the OpenAI API.
What are the benefits of having separate organizations for each business unit or product feature?
Answer:
- Reducing risk of hitting rate limits
- Improving insights into usage and billing
- Removing single failure points
Managing organizations will ensure that users can have an interruption-free experience that translates the power of AI into real business value.
OpenAI’s Text and Chat Capabilities
OpenAI’s GPT series of language models have created headlines the world over. In this chapter, you’ll use these models for generating and transforming text content, for classification tasks like categorization and sentiment analysis, and finally, to create your very own AI-powered chatbot!
Text completions
Text completions: In this chapter, we’ll take a deeper dive into the rich text and chat functionality the API has to offer.
Recap…: So far, we’ve used the Completions endpoint to answer questions, but the model’s capabilities go far beyond this. To understand where these capabilities come from, let’s take a step back and discuss how text completion works.
- Text completions for Q&A
1
2
3
4
5
6
7
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="How many days are in October?"
)
print(response.choices[0].text)
[out]:
October has 31 days.
- What is a text completion?: When we send a prompt to the Completions endpoint, the model returns the text that it believes is most likely to complete the prompt, which it infers based on the data the model was developed on. If we send “Life is like a box of chocolates” to the model, it correctly completes the quote with high probability. We say high probability here because the model results are non-deterministic, so the model may only correctly complete the quote 98 times out of 100.
- Text most likely to complete the prompt
1
2
3
4
5
6
7
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Life is like a box of chocolates."
)
print(response.choices[0].text)
[out]:
You never know what you're going to get.
- Response is non-deterministic (inherently random)
- Controlling response randomness: There are many use cases where randomness is undesirable; think of a customer service chatbot - we wouldn’t want the chatbot to provide different guidance to customers with the same issue. However, we would like the model to be flexible to different inputs, so there’s often a trade off in the amount of randomness. We can control the amount of randomness in the response using the temperature parameter. temperature is set to one by default, but can range from zero to two, where zero is almost entirely deterministic and two is extremely random. If we add a temperature of two here, we can see the model completes the prompt by putting its own bizarre spin on Forrest Gump’s famous quote.
temperature: control on determinism- Ranges from 0 (highly deterministic) to 2 (very random)
1
2
3
4
5
6
7
8
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Life is like a box of chocolates.",
temperature=2
)
print(response.choices[0].text)
[out]:
You never know what bitter constraints to any fate journey of Enlightenment you instead be forced...
- Content transformation: Because the text completion model returns the most likely text to follow the prompt, it can be used to solve a number of tasks besides answering questions, including text content generation and transformation. Text transformation involves changing text based on an instruction, and examples include find and replace, summarization, and copyediting. For example, we can use the API to update the name, pronouns, and job title in a bio. Notice that the prompt starts with the instruction, then the text to transform. We’ve also used triple quotes to define a multi-line prompt for ease of readability and processing. Then, as before, we send this prompt to the Completions endpoint of the API. Voilà! We have our updated text. Even with a find and replace tool, this task would normally require us to specify every word to update.
- Changing text based on an instruction
- Find and replace
- Summarization
- Copyediting
- Changing text based on an instruction
1
2
3
4
5
6
7
8
9
prompt = """Update name to Maarten, pronouns to he/him, and job title to Senior Content Developer: Joanne is a Content Developer at DataCamp. Her favorite programming language is R, which she uses for her statistical analyses."""
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt
)
print(response.choices[0].text)
[out]:
Maarten is a Senior Content Developer at DataCamp. His favorite programming language is R, which he uses for his statistical analyses.
- Content generation: Text completions are also used to generate new text content from a prompt providing an instruction. For example, we can create a request to generate a tagline for a new hot dog stand - the API does a good job, and even includes a subtle pun!
1
2
3
4
5
6
7
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Create a tagline for a new hot dog stand."
)
print(response.choices[0].text)
[out]:
"Frankly, we've got the BEST dogs in town!"
- Controlling response length: By default, the response from the API is quite short, which may be unsuitable for many use cases. The max_tokens parameter can be used to control the maximum length of the response.
- Default
max_tokens
- Default
1
2
3
4
5
6
7
8
9
10
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Write a haiku about AI."
)
print(response.choices[0].text)
[out]:
AI so powerful
Computers that think and learn
Superseding
max_tokens=30
1
2
3
4
5
6
7
8
9
10
11
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Write a haiku about AI.",
max_tokens=30
)
print(response.choices[0].text)
[out]:
A machine mind thinks
Logic dictates its choices
Mankind ponders anew
- Understanding tokens: Tokens are a unit of one or more characters used by language models to understand and interpret text. In English, one token translates to about four characters, and 100 tokens to 75 words, so if our use case requires no more than around 150 words, a max_tokens of 200 would be a good choice.

- In English:
- 1 token ~ 4 characters
- 100 tokens ~ 75 words
- Example: 150 words →
max_tokens=200
- Returning to cost: Increasing max_tokens will likely also increase the usage cost for each request. Recall that the usage costs are dependent on the model used and the amount of generated text. Each model is actually priced based upon the cost per 1000 tokens, where input tokens, the tokens used in the prompt, and output tokens, the generated text, can be priced differently. When scoping the potential cost of a new AI feature, the first step is often a back-of-the-envelope calculation to determine the cost per unit time.
- Increasing max_tokens increases cost
- Usage costs dependent on amount of generated text
- Models are priced by cost/1K tokens
- Input and output tokens can be priced differently
- Scoping feature cost often starts with a rough calculation:
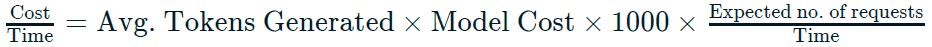
- OpenAI pricing
Find and replace
Text completion models can be used for much more than answering questions. In this exercise, you’ll explore the model’s ability to transform a text prompt.
Find-and-replace tools have been around for decades, but they are often limited to identifying and replacing exact words or phrases. You’ve been provided with a block of text discussing cars, and you’ll use a completion model to update the text to discuss planes instead, updating the text appropriately.
Warning**: if you send many requests or use lots of tokens in a short period, you may hit your rate limit and see an openai.error.RateLimitError. If you see this error, please wait a minute for your quota to reset and you should be able to begin sending more requests. Please see OpenAI’s rate limit error support article for more information.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Set your API key
# client = OpenAI(api_key=api_key) # creted at the top of the notebook
prompt = """Replace car with plane and adjust phrase:
A car is a vehicle that is typically powered by an internal combustion engine or an electric motor. It has four wheels, and is designed to carry passengers and/or cargo on roads or highways. Cars have become a ubiquitous part of modern society, and are used for a wide variety of purposes, such as commuting, travel, and transportation of goods. Cars are often associated with freedom, independence, and mobility."""
# Create a request to the Completions endpoin
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=100
)
# Extract and print the response text
print(response.choices[0].text)
1
A plane is an aircraft that is typically powered by jet engines or propellers. It has wings, and is designed to transport passengers and/or cargo through the air. Planes have become an essential means of transportation in modern society, and are used for various purposes, such as business travel, tourism, and shipping. Planes are often associated with speed, efficiency, and global connectivity.
Quickly adapting text in this way was impossible before AI came along, and now, anyone can do this with just a few lines of code and an OpenAI API key. Head on over to the next exercise to try another transformation task.
Text summarization
One really common use case for using OpenAI’s models is summarizing text. This has a ton of applications in business settings, including summarizing reports into concise one-pagers or a handful of bullet points, or extracting the next steps and timelines for different stakeholders.
In this exercise, you’ll summarize a passage of text on financial investment into two concise bullet points using a text completion model.
1
2
3
4
5
6
7
8
9
10
11
prompt = """Summarize the following text into two concise bullet points:
Investment refers to the act of committing money or capital to an enterprise with the expectation of obtaining an added income or profit in return. There are a variety of investment options available, including stocks, bonds, mutual funds, real estate, precious metals, and currencies. Making an investment decision requires careful analysis, assessment of risk, and evaluation of potential rewards. Good investments have the ability to produce high returns over the long term while minimizing risk. Diversification of investment portfolios reduces risk exposure. Investment can be a valuable tool for building wealth, generating income, and achieving financial security. It is important to be diligent and informed when investing to avoid losses."""
# Create a request to the Completions endpoint
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=400,
temperature=0)
print(response.choices[0].text)
1
2
- Investment involves committing money or capital to an enterprise in order to obtain added income or profit.
- Careful analysis, risk assessment, and diversification are important for making successful investments that can build wealth and achieve financial security.
Summarization is one of the most widely-used capabilities of OpenAI’s completions models. This has many applications in business to condense and personalize reports and papers to a particular length and audience.
Content generation
AI is playing a much greater role in content generation, from creating marketing content such as blog post titles to creating outreach email templates for sales teams.
In this exercise, you’ll harness AI through the Completions endpoint to generate a catchy slogan for a new restaurant. Feel free to test out different prompts, such as varying the type of cuisine (e.g., Italian, Chinese) or the type of restaurant (e.g., fine-dining, fast-food), to see how the response changes.
1
2
3
4
5
6
7
# Create a request to the Completions endpoint
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt='create a slogan for a new restaurant',
max_tokens=100)
print(response.choices[0].text)
1
"Savor the flavors, indulge in every bite at our restaurant."
AI-generated content, including text, images, audio, and even video, is becoming more and more mainstream, particularly for industries and roles that require creating user-facing content, such as media and marketing. Head on over to the next video to learn about more unexpected and impressive tasks that you can complete with OpenAI’s models.
Text completions for classification tasks
Text completions for classification tasks: So we’ve seen that the text completions models are pretty flexible, and can do much more than answer questions. In this lesson, we’ll take this a step further to discuss classification tasks.
- Classification tasks: Classification tasks involve assigning a label to a piece of information. This can be identification, such as identifying the language used in a piece of text, categorization, such as sorting geographical locations into countries and US states, or even classifying a statement’s sentiment, that is, whether it sounds positive or negative. The Completions endpoint can be used for all of these tasks, providing the model has sufficient knowledge of the subject area and that the prompt contains the necessary context.
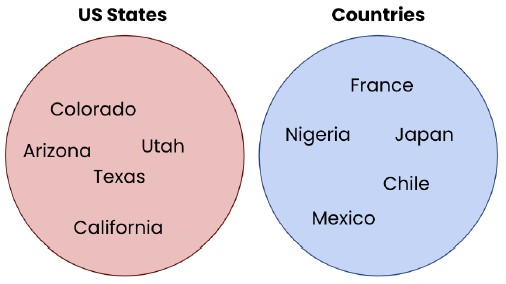
- Task that involves assigning a label to information
- Identifying the language from text
- Categorization
- Classifying sentiment
- Completions endpoint can perform these tasks, providing:
- Model has sufficient knowledge
- Prompt contains sufficient context
- Categorizing animals: Let’s use the Completions endpoint to categorize these animals. Printing the response, we see that the model categorized the animals into mammals, fish, and reptiles. This might be what we were looking for, but there’s an almost infinite number of ways to categorize something, so it’s best practice to state the desired categories in the prompt.
1
2
3
4
5
6
7
8
9
10
11
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Classify the following animals into categories: zebra, crocodile, blue whale, polar bear, salmon, dog.",
max_tokens = 50
)
print(response.choices[0].text)
[out]:
Mammals: Zebra, Polar Bear, Dog
Fish: Salmon
Reptiles: Crocodile
- Specifying groups: We can update the prompt to categorize animals into those with and without fur, and the model responds with the desired categories.
1
2
3
4
5
6
7
8
9
10
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Classify the following animals into animals with fur and without: zebra, crocodile, dolphin, polar bear, salmon, dog.",
max_tokens=50
)
print(response.choices[0].text)
[out]:
Animals with fur: Dog, Polar Bear, Zebra
Animals without fur: Crocodile, Dolphin, Salmon
- Classifying sentiment: Let’s look at an example of classifying sentiment. Let’s say we received a number of online reviews to our restaurant, and we want to extract the sentiment, as numbers one to five, for further analysis. We can write a prompt with the instruction to classify sentiment, and a list of statements, pass it to the Completions endpoint, and print the response. The model does a good job; however, because we didn’t specify how to classify the categories, the model didn’t realize we actually wanted a numerical output. We can update our prompt so the model has the context on what the categories should be. The updated response contains a reasonable numerical representation of the sentiment of each statement.
1
2
3
4
5
6
7
8
9
10
11
12
prompt = """Classify sentiment in the following statements:
1. The service was very slow
2. The steak was awfully tasty!
3. Meal was decent, but I've had better.
4. My food was delayed, but drinks were good.
"""
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=50
)
print(response.choices[0].text)
- The service was very slow: Negative
- The steak was awfully tasty!: Positive
- Meal was decent, but I’ve had better.: Neutral
- My food was delayed, but drinks were good.: Mixed
1
2
3
4
5
6
7
8
9
10
11
12
prompt = """Classify sentiment as 1-5 (bad-good) in the following statements:
1. The service was very slow
2. The steak was awfully tasty!
3. Meal was decent, but I've had better.
4. My food was delayed, but drinks were good.
"""
[out]:
1. The service was very slow: 1
2. The steak was awfully tasty!: 5
3. Meal was decent, but I've had better.: 3
4. My food was delayed, but drinks were good.: 2
- Zero-shot vs. one-shot vs. few-shot prompting: The prompts we’ve used so far are examples of a so-called zero-shot prompts, where we haven’t provided any examples in the prompt for the model to learn from. For many use cases, this may be fine, but for more complex cases where the model may not have a good understanding of the subject matter or task, we may need to provide examples for it to learn from. If one example is provided in the prompt, it’s called one-shot prompting, and for more than one, it’s called few-shot prompting. Providing examples in the prompt for the model to learn from is called in-context learning, as the model is learning from the context we’re providing. Let’s return to sentiment analysis to give these prompting techniques a go.
- Zero-shot prompting: no examples provided
- In-context learning:
- One-shot prompting: one example provided
- Few-shot prompting: a handful of examples provided
- One-shot prompting: We’re again dealing with restaurant reviews, but this time, we want the sentiment to be more specific. To do this, we provide one example in the prompt, clearly separating the input and output. Sending this to the Completions endpoint and printing the result shows that the model accurately analyzed the statement, but that it didn’t provide any more detail than when we used a zero-shot prompt. In more complex cases, one example is not enough, and we’ll need to experiment to determine the number of shots the model needs for the use case.
1
2
3
4
5
6
7
8
9
10
11
12
prompt = """Classify sentiment in the following statements:
The service was very slow // Disgruntled
Meal was decent, but I've had better. //
"""
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt
)
print(response.choices[0].text)
[out]:
Neutral
- Few-shot prompting: Let’s extend the prompt to provide three examples. Running the same code again, we see that the model was much more specific.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
prompt = """Classify sentiment in the following statements:
The service was very slow // Disgruntled
The steak was awfully tasty! // Delighted
Good experience overall. // Satisfied
Meal was decent, but I've had better. //
"""
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt
)
print(response.choices[0].text)
[out]:
Mildly dissatisfied
- Let’s practice!: Hopefully you’re starting to grasp just how many problems can be solved using the OpenAI API, and how important prompts are to obtaining good results. Time to practice!
Classifying text sentiment
As well as answering questions, transforming text, and generating new text, Completions models can also be used for classification tasks, such as categorization and sentiment classification. This sort of task requires not only knowledge of the words but also a deeper understanding of their meaning.
In this exercise, you’ll explore using Completions models for sentiment classification using reviews from an online shoe store called Toe-Tally Comfortable:
- Unbelievably good!
- Shoes fell apart on the second use.
- The shoes look nice, but they aren’t very comfortable.
- Can’t wait to show them off!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Create a request to the Completions endpoint
# Create a request to the Completions endpoint
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="""classify sentiment as negative, positive, or neutral in the following statements:
1. Unbelievably good!
2. Shoes fell apart on the second use.
3. The shoes look nice, but they aren't very comfortable.
4. Can't wait to show them off!
""",
max_tokens=100
)
print(response.choices[0].text)
1
2
3
4
1. Positive
2. Negative
3. Neutral
4. Positive
Categorizing companies
In this exercise, you’ll use a Completions model to categorize different companies. At first, you won’t specify the categories to see how the model categorizes them. Then, you’ll specify the categories in the prompt to ensure they are categorized in a desirable and predictable way.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
prompts = [
"Categorize the following companies: Apple, Microsoft, Saudi Aramco, Alphabet, Amazon, Berkshire Hathaway, NVIDIA, Meta, Tesla, and LVMH",
"Categorize the following companies into the categories Tech, Energy, Luxury Goods, or Investment: Apple, Microsoft, Saudi Aramco, Alphabet, Amazon, Berkshire Hathaway, NVIDIA, Meta, Tesla, and LVMH"
]
for prompt in prompts:
# Create a request to the Completions endpoint
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=100,
temperature=0.5
)
print(response.choices[0].text)
print('\n')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
1. Technology: Apple, Microsoft, Alphabet, Amazon, NVIDIA, Tesla
2. Energy: Saudi Aramco
3. Conglomerate: Berkshire Hathaway
4. Social Media: Meta
5. Luxury Goods: LVMH
Apple - Tech
Microsoft - Tech
Saudi Aramco - Energy
Alphabet - Tech
Amazon - Tech
Berkshire Hathaway - Investment
NVIDIA - Tech
Meta - Tech
Tesla - Energy
LVMH - Luxury Goods
Categorically commendable! Providing a more specific prompt gave you much greater control over the model’s response. In the next video, you’ll learn about OpenAI’s chat models, which are the engines behind popular AI chatbot applications like ChatGPT. You can do this!
Chat completions with GPT
Chat completions with GPT: Welcome back! In this video, we’ll learn to unlock the chat capabilities from the OpenAI API, which underpin popular applications like ChatGPT. Let’s get started!
- The Chat Completions endpoint: The Chat Completions endpoint allows us to have multi-turn conversations with a model, so we can build on our previous prompts depending on how the model responds. Additionally, chat models often perform just as well as Completions models on single-turn tasks. Compared to the Completions endpoint, Chat Completion allows for better customizability of the response through the use of roles, which we’ll discuss in a moment. Finally, there’s also a cost benefit to using chat completions models over completions. The cost benefit and flexibility of being able to have multi-turn conversations, means that developers quite often choose a chat model when building applications on the OpenAI API.
- Multi-turn conversations
- Also performs well on single-turn
- Better customizability of response through the use of roles
- Cost benefit: gpt-3.5-turbo is cheaper than gpt-3.5-turbo-instruct
- Multi-turn conversations
- Roles: Roles are at the heart of how chat models function. There are three main roles: the system, the user, and the assistant. The system role allows the user to specify a message to control the behavior of the assistant. For example, for a customer service chatbot, we could provide a system message stating that the assistant is a polite and helpful customer service assistant. The user provides an instruction to the assistant, and the assistant responds. One of the interesting things about chat models, is that the user can also provide assistant messages. These are often utilized to provide examples to help the model better understand the user’s desired response. We’ll discuss multi-turn conversations in the next video; for now, we’ll get familiar with using chat models for single-turn tasks.
- System: controls assistant’s behavior
- User: instruct the assistant
- Assistant: response to user instruction
- Can also be written by the user to provide examples
- Request setup: Making a request to the Chat Completions endpoint is very similar to the Completions endpoint. Instead of calling the create method on client.completions, we call it on client.chat.completions; there’s also different models for these two endpoints. The main difference is in the way that prompts are provided. For the Completions endpoint, the prompt is passed as a string for the model to complete. Due to the greater customizability of chat models through the use of roles, the prompt is provided in a different way.
- Completions
1
response = client.completions.create(model="gpt-3.5-turbo-instruct", prompt="____")
- Chat Completions
1
response = client.chat.completions.create(model="gpt-3.5-turbo", messages=____)
- Prompt setup: The prompt is set up by creating a list of dictionaries, where each dictionary provides content to one of the roles. The messages often start with the system role followed by alternating user and assistant messages. The system role here instructs the assistant to act as a data science tutor that speaks concisely.
1
2
messages=[{"role": "system", "content": "You are a data science tutor who speaks concisely."},
{"role": "user", "content": "What is the difference between mutable and immutable objects?"}]
- Making a request: Let’s add these messages into the request code and print the response.
1
2
3
4
5
6
7
response = client.chat.completions.create(model="gpt-3.5-turbo",
messages=[{"role": "system",
"content": "You are a data science tutor who speaks concisely."},
{"role": "user",
"content": "What is the difference between mutable and immutable objects?"}]
)
print(response)
- The response: The response we receive is very similar to the Completions endpoint, where the assistant’s text response is nested inside the choices attribute. We’ll start by accessing the
1
2
3
4
5
6
7
8
9
10
ChatCompletion(id='chatcmpl-8SM9TkxEkunyu6gLVJv3OvSmnxXvX',
choices=[Choice(finish_reason='stop',
index=0,
message=ChatCompletionMessage(content='Mutable objects can be modified after they are created, whereas immutable objects cannot be modified once they are created.',
role='assistant', function_call=None, tool_calls=None))],
created = 1701769027,
model = 'gpt-3.5-turbo-0613',
object = 'chat.completion',
system_fingerprint = None,
usage = CompletionUsage(completion_tokens=21, prompt_tokens=33, total_tokens=54))
- Extracting the text: choices attribute, which returns a list with a single element, a Choice object with its own attributes. Next, we’ll subset the first element from that list to get to the Choice object. Finally, we can access the content by first accessing the message attribute of the Choice object, and then the content attribute of the ChatCompletionMessage object. We can see that the assistant stayed true to the system message - only using a single sentence in its concise explanation.
1
2
3
4
5
6
7
8
print(response.choices)
[out]:
[Choice(finish_reason='stop',
index=0,
message=ChatCompletionMessage(
content='Mutable objects can be modified after they are created, whereas immutable objects cannot be modified once they are created.',
role='assistant', function_call=None, tool_calls=None))]
1
2
3
4
5
6
7
8
print(response.choices[0])
[out]:
Choice(finish_reason='stop',
index=0,
message=ChatCompletionMessage(
content='Mutable objects can be modified after they are created, whereas immutable objects cannot be modified once they are created.',
role='assistant', function_call=None, tool_calls=None))
1
2
3
4
print(response.choices[0].message.content)
[out]:
Mutable objects can be modified after they are created, whereas immutable objects cannot be modified once they are created.
- Let’s practice!: In the next video, you’ll learn how to extend this to multi-turn tasks, but for now, time for some practice!
The Chat Completions endpoint
The models available via the Chat Completions endpoint can not only perform similar single-turn tasks as models from the Completions endpoint, but can also be used to have multi-turn conversations.
To enable multi-turn conversations, the endpoint supports three different roles:
- System: controls assistant’s behavior
- User: instruct the assistant
- Assistant: response to user instruction
In this exercise, you’ll make your first request to the Chat Completions endpoint to answer the following question:
What is the difference between a for loop and a while loop?
Instructions:
- Create a request to the Chat Completions endpoint using both system and user messages to answer the question, What is the difference between a for loop and a while loop?
- Extract and print the assistant’s text response.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Create a request to the Chat Completions endpoint
response = client.chat.completions.create(
model="gpt-3.5-turbo",
max_tokens=150,
messages=[
{"role": 'system',
"content": "You are a helpful data science tutor."},
{'role': 'user',
'content': "What is the difference between a for loop and a while loop?"}
]
)
# Extract and print the assistant's text response
print(response.choices[0].message.content)
1
2
3
4
5
A for loop and a while loop are both used for iterating through a sequence of statements or instructions. The main difference between the two lies in their syntax and the conditions under which they are typically used.
- A for loop is used when you know in advance how many times you want to iterate through a block of code. It is structured to have an initialization step, a condition for when to keep looping, and an update step that is executed after each iteration. For example, you might use a for loop to iterate through all the elements of a list.
- A while loop, on the other hand, is used when you want to repeatedly execute a block of code as long as a certain condition is true. The loop continues iterating as long as the
Exemplary explanation! AI models have massively augmented how people approach upskilling and learning; in the next exercise, you’ll take this up a level to use the model for code explanation.
Code explanation
One of the most popular use cases for using OpenAI models is for explaining complex content, such as technical jargon and code. This is a task that data practitioners, software engineers, and many others must tackle in their day-to-day as they review and utilize code written by others.
In this exercise, you’ll use the OpenAI API to explain a block of Python code to understand what it is doing.
Instructions:
- Create a request to the Chat Completions endpoint to send
instructionto thegpt-3.5-turbo model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
instruction = """Explain what this Python code does in one sentence:
import numpy as np
heights_dict = {"Mark": 1.76, "Steve": 1.88, "Adnan": 1.73}
heights = heights_dict.values()
print(np.mean(heights))
"""
# Create a request to the Chat Completions endpoint to send instruction to the gpt-3.5-turbo model.
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system",
"content": "You are a helpful Python programming tutor."},
{"role": "user",
"content": instruction}
],
max_tokens=100
)
print(response.choices[0].message.content)
1
This Python code calculates the mean of the heights of individuals stored in a dictionary using the NumPy library.
Awesome work! Think of how useful this is for reviewing other people’s code; it would even be possible to construct a prompt to write documentation or code comments for some code using this model. Continue on to discover how chat completions can be used to start building chatbots on the chat completions models!
Multi-turn chat completions with GPT
Multi-turn chat completions with GPT: Great work so far! In this video, we’ll begin to unleash the full potential of chat models by creating multi-turn conversations.
Chat completions for single-turn tasks: Recall that messages are sent to the Chat Completions endpoint as a list of dictionaries, where each dictionary provides content to a specific role from either system, user, or assistant. For single turn tasks, no content is sent to the assistant role - the model relies only on its existing knowledge, the behaviors sent to the system role, and the instruction from the user.
1
2
3
4
5
6
7
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "system",
"content": "You are a data science tutor."},
{"role": "user",
"content": "What is the difference between mutable and immutable objects?"}]
)
- System: controls assistant’s behavior
- User: instruct the assistant
- Assistant: response to user instruction
- Providing examples: Providing assistant messages can be a simple way for developers to steer the model in the right direction without having to surface anything to end-users. If we created a data science tutor application, we could provide a few examples of data science questions and answers that would be sent to the API along with the user’s question. Let’s improve our data science tutor by providing an example. Between the system message outlining the assistant’s behavior and the user’s question to answer, we’ll add a user and assistant message to serve as an ideal example for the model. We add a user message containing a question on a similar topic and a response that we consider ideally written for our use case. The model now not only has its pre-existing understanding, but also a working example to guide its response.
- Steer model in the right direction
- Nothing surfaced to the end-user
- Example: Data Science Tutor Application
- Provide examples of data science questions and answers
1
2
3
4
5
6
7
8
9
10
11
12
13
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system",
"content": "You are a data science tutor who speaks concisely."},
{"role": "user",
"content": "How do you define a Python list?"},
{"role": "assistant",
"content": "Lists are defined by enclosing a comma-separated sequence of objects inside square brackets [ ]."},
{"role": "user",
"content": "What is the difference between mutable and immutable objects?"}
]
)
- The response: With an example to work with, the assistant provides a succinct and accurate response that’s more in-line with our expectations.
1
2
3
4
print(response.choices[0].message.content)
[out]:
Mutable objects are objects whose values can change after they are created. Examples of mutable objects in Python include lists, sets and dictionaries. Immutable objects are objects whose values cannot change after they are created. Examples of immutable objects in Python include strings, numbers and tuples.
- Storing responses: Another common use for providing assistant messages is to store responses. Storing responses means that we can create a conversation history, which we can feed into the model to have back-and-forth conversations. This is exactly what goes on underneath AI chatbots like ChatGPT!
- Create conversation history
- Create back-and-forth conversations
- Building a conversation: To code a conversation, we’ll need to create a system so that when a user message is sent, and an assistant response is generated, they are fed back into the messages and stored to be sent with the next user message. Then, when a new user message is provided, the model has the context from the conversation history to draw from. This means that if we introduce ourselves in the first user message, then ask the model what our name is in the second, it should return the correct answer, as it has access to the conversation history. Let’s start to code this in Python.
- Coding a conversation: We start by defining some base messages, which can include the system message and any other developer-written examples. Then we can define a list of questions. Here we ask why Python is popular and then ask it to summarize the response provided in one sentence, which requires context on the previous response. Because we want a response for each question, we start by looping over the user_qs list. Next, to prepare the user message string for the API, we need to create a dictionary and add it to the list of messages using the list append method. We can now send the messages to the Chat Completions endpoint and store the response. We extract the assistant’s message by subsetting from the API response, converting to a dictionary so it’s in the correct format, then adding it to the messages list for the next iteration. Finally, we’ll add two print statements so the output is a conversation between the user and assistant written as a script.

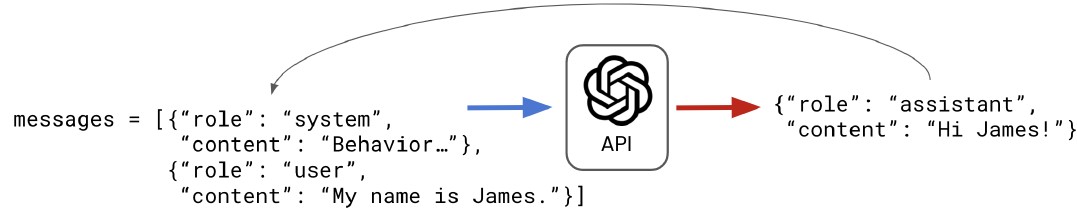


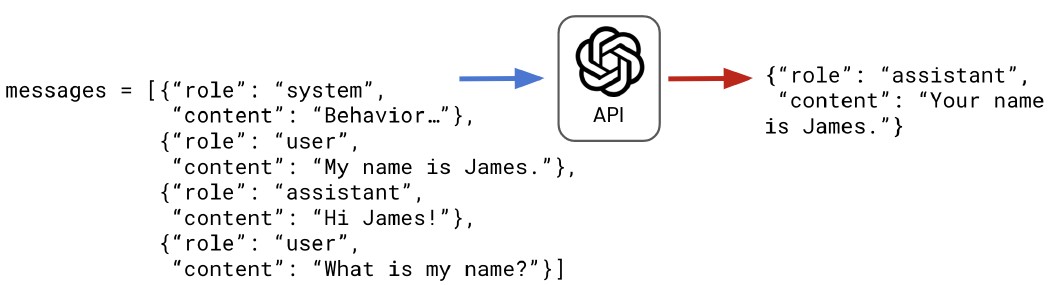
1
2
3
4
5
6
7
8
9
10
11
12
13
messages = [{"role": "system",
"content": "You are a data science tutor who provides short, simple explanations."}]
user_qs = ["Why is Python so popular?", "Summarize this in one sentence."]
for q in user_qs:
print("User: ", q)
user_dict = {"role": "user", "content": q}
messages.append(user_dict)
response = client.chat.completions.create(model="gpt-3.5-turbo", messages=messages)
assistant_dict = {"role": "assistant", "content": response.choices[0].message.content}
messages.append(assistant_dict)
print("Assistant: ", response["choices"][0]["message"]["content"], "\n")
- Conversation with an AI: We can see that we were successfully able to provide a follow-up correction to the model’s response without having to repeat our question or the model’s response.
User: Why is Python so popular?
Assistant: Python is popular for many reasons, including its simplicity, versatility, and wide range of available libraries. It has a relatively easy-to-learn syntax that makes it accessible to beginners and experts alike. It can be used for a variety of tasks, such as data analysis, web development, scientific computing, and machine learning. Additionally, Python has an active community of developers who contribute to its development and share their knowledge through online resources and forums.
User: Summarize this in one sentence.
Assistant: Python is popular due to its simplicity, versatility, wide range of libraries, and active community of developers.
- Let’s practice!: You’ve learned about the key functionality underpinning many AI-powered chatbots and assistants—time to begin creating your own!
In-context learning
For more complex use cases, the models lack the understanding or context of the problem to provide a suitable response from a prompt. In these cases, you need to provide examples to the model for it to learn from, so-called in-context learning.
In this exercise, you’ll improve on a Python programming tutor built on the OpenAI API by providing an example that the model can learn from.
Here is an example of a user and assistant message you can use, but feel free to try out your own:
- User → Explain what the min() function does.
- Assistant → The min() function returns the smallest item from an iterable.
Instructions:
- Add a similar coding example in the form of user and assistant messages to
messagesso the model can learn more about the desired response.
1
2
3
4
5
6
7
8
9
10
11
response = client.chat.completions.create(
model="gpt-3.5-turbo",
# Add a user and assistant message for in-context learning
messages=[
{"role": "system", "content": "You are a helpful Python programming tutor."},
{"role": "user", "content": "Explain what the type() function does."},
{"role": "assistant", "content": "The type() function returns the type of an object."}
]
)
print(response.choices[0].message.content)
1
For example, if you pass an integer to the type() function, it will return <class 'int'>. If you pass a string, it will return <class 'str'>, and so on. The type() function can be helpful when you need to check the type of a variable or object in your program.
Providing examples helps mitigate undesirable or inaccurate model responses, so they’re a good practice in many use cases. In the next exercise, you’ll take a major step in your application development journey: beginning to construct your first AI-powered chatbot!
Creating an AI chatbot
An online learning platform called Easy as Pi that specializes in teaching math skills has contracted you to help develop an AI tutor. You immediately see that you can build this feature on top of the OpenAI API, and start to design a simple proof-of-concept (POC) for the major stakeholders at the company. This POC will demonstrate the core functionality required to build the final feature and the power of the OpenAI’s GPT models.
Example system and user messages have been provided for you, but feel free to play around with these to change the model’s behavior or design a completely different chatbot!
Instructions:
- Create a dictionary to house the user message in a format that can be sent to the API; then append it to
messages. - Create a Chat request to send
messagesto the model. - Extract the assistant’s message, convert it to a dictionary, and append it to
messages.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
messages = [{"role": "system", "content": "You are a helpful math tutor."}]
user_msgs = ["Explain what pi is.", "Summarize this in two bullet points."]
for q in user_msgs:
print("User: ", q)
# Create a dictionary for the user message from q and append to messages
user_dict = {"role": "user", "content": q}
messages.append(user_dict)
# Create the API request
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
max_tokens=100
)
# Convert the assistant's message to a dict and append to messages
assistant_dict = {"role": "assistant", "content": response.choices[0].message.content}
messages.append(assistant_dict)
print("Assistant: ", response.choices[0].message.content, "\n")
1
2
3
4
5
6
User: Explain what pi is.
Assistant: Pi (π) is a mathematical constant that represents the ratio of a circle's circumference to its diameter. It is an irrational number, which means it cannot be expressed as a simple fraction and its decimal representation goes on infinitely without repeating. Pi is commonly approximated as 3.14 or represented by the Greek letter π. It is used in a wide variety of mathematical and scientific applications, such as geometry, trigonometry, physics, and engineering.
User: Summarize this in two bullet points.
Assistant: - Pi (π) is a mathematical constant representing the ratio of a circle's circumference to its diameter.
- It is an irrational number, approximated as 3.14, and widely used in various mathematical and scientific fields.
Congratulations on your very first chatbot! Building a conversation history into your applications will allow users to interact much more efficiently by not having to repeat context over and over. In the next chapter, you’ll deep dive into OpenAI’s other models for moderation and audio transcription and translation. You’ll cap off the chapter by bringing everything together, learning how you can combine models together to automate more complex tasks. See you there!
Going Beyond Text Completions
OpenAI has not only developed models for text generation but also for text moderation and audio transcription and translation. You’ll learn to use OpenAI’s moderation models to detect violations of their terms of use—a crucial function in user-facing applications. You’ll also discover how the Whisper model can be used to transcribe and translate audio from different languages, which has huge applications in automated meeting notes and caption generation.
Text moderation with OpenAI
Text moderation: Up to this point,
- Going beyond text completions…: we’ve used OpenAI’s models for completing text in some way, whether that’s answering questions, classifying statements, or editing text. In this chapter, we’ll go further into the API capabilities, including text moderation, audio transcription and translation, and even combining models together. Let’s start with text moderation.
- Completions → generate new text output using text prompt
- Beyond completions:
- Text moderation
- Audio transcription and translation
- Combining models together
- Text moderation: Text moderation is the process of identifying text that is inappropriate for the context it is being used in. In online communities like social networks and chat rooms, moderation is crucial to prevent the exchange of harmful and offensive content. Traditionally, this moderation was done by-hand, where a team of moderators flagged the content that breached usage rules. More recently this was done by algorithms that detected and flagged content containing particular words. Manual moderation is extremely time-consuming and, if multiple moderators are involved, introduces a subjective element that may result in inconsistencies. Keyword pattern matching, although much quicker and able to run round-the-clock, can be a clumsy tool that misses some malicious content while accidentally flagging perfectly good content because it doesn’t understand nuance or the context of the discussion. To prevent the misuse of their own models, OpenAI have developed moderation models to flag content that breaches their usage policies.
- Identifying inappropriate content
- Traditionally, moderators flag content by-hand
- Time-consuming
- Traditionally, keyword pattern matching
- Lacks nuance and understanding of context
- Violation categories: The OpenAI moderation models can not only detect violations of their terms of use, but also differentiate the type of violation across different categories, including violence and hate speech.
- Usage Policies
- Moderation Overview
- Identify violations of terms or use
- Differentiate violation type by category
- Violence
- Hate Speech
- Creating a moderations request: To create a request to the Moderations endpoint, we call the create method on client.moderations, and specify that we want the latest moderation model, which often performs the best. If a use case requires greater stability in classifications over time, we can also specify particular model versions. Next is the input, which is the content that the model will consider. This statement could easily be classed as violent by traditional moderation systems that worked by flagging particular keywords. Let’s see what OpenAI’s moderation model makes of it.
1
2
3
4
5
6
7
from openai import OpenAI
client = OpenAI(api_key="ENTER API KEY")
response = client.moderations.create(
model="text-moderation-latest",
input="I could kill for a hamburger."
)
- Interpreting the results: We’ll dump the response to a dictionary for easier readability. The output is similar other endpoints. There are three useful indicators that can be used for moderation: categories, representing whether the model believed that the statement violated a particular category, category_scores, an indicator of the model’s confidence of a violation, and finally, flagged, whether it believes the terms of use have been violated in any way. Let’s extract the category_scores from the response for a closer look.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
print(response.model_dump())
[out]:
{'id': 'modr-8S80XeaVqvs4mmbufDBP9gTAmEGXP',
'model': 'text-moderation-006',
'results':
[{'categories': {'harassment': False,
'harassment_threatening': False,
'hate': False,
'hate_threatening': False,
...},
'category_scores': {'harassment': 2.775940447463654e-05,
'harassment_threatening': 1.3526056363843963e-06,
'hate': 2.733528674525587e-07,
'hate_threatening': 4.930571506633896e-08,
...},
'flagged': False}]
}
categoriestrue/falseindicator of category violation
category_scores- Confidence of a violation
flaggedtrue/falseindicator of a violation
- Interpreting the category scores: The category_scores are float values for each category indicating the model’s confidence of a violation. They can be extracted from the results attribute, and through that, the category_scores attribute. The scores can be between 0 and 1, and although higher values represent higher confidence, they should not be interpreted as probabilities. Notice from the small numbers, including in the violence category, that OpenAI’s moderation model did not interpret the statement as containing violent content. The model used the rest of the sentence to interpret the context and accurately infer the statement’s meaning.
1
2
3
4
5
6
7
8
9
10
print(response.results[0].category_scores)
[out]:
CategoryScores(harassment=2.775940447463654e-05,
harassment_threatening=1.3526056363843963e-06,
hate=2.733528674525587e-07,
hate_threatening=4.930571506633896e-08,
...,
violence=0.0500854030251503,
...)
- Larger numbers → greater certainty of violation
- Numbers ≠ probabilities
- Considerations for implementing moderation: The beauty of having access to these category scores means that we don’t have to depend on the final true/false results outputted by the model, we can instead test the model on data from our own particular use case, and set our own thresholds based on the results. For some use cases, such as student communications in a school, strict thresholds may be chosen that flag more content, even if it means accidentally flagging some non-violations. The goal here would be to minimize the number of missed violations, so-called false negatives. Other use cases, such as communications in law enforcement, may use more lenient thresholds so reports on crimes aren’t accidentally flagged. Incorrectly flagging a crime report here would be an example of a false positive.
- Determine appropriate thresholds for each use case
- Stricter thresholds may result in fewer false negatives
- More lenient thresholds may result in fewer false positives
Why use text moderation models?
Text moderation is a vital component of most social media platforms, internet chatrooms, and many other user-facing systems. It serves the purpose of preventing the distribution and promotion of inappropriate content, such as hate speech.
In this exercise, you’ll compare OpenAI’s text moderation model to traditional methods of moderation: manual moderation and keyword pattern matching.
Instructions:
- Classify the statements as being properties of OpenAI’s moderation model, keyword pattern matching, or manual moderation.
Here are the categorizations for the given statements:
- OpenAI’s Moderation model
- Evaluates content based on specific violation categories.
- A model that uses all of the words to inform its decision.
- Outputs confidence of text violation.
- Designed to moderate the prompts and responses to and from OpenAI models.
- Keyword Pattern Matching
- Don’t understand context.
- Manual Moderation
- Expensive.
- Requires 24/7 support.
- Inconsistent classification.
Moderation models represent a significant advancement in the way that content is moderated. Head on over to the next exercise to use OpenAI’s Moderation model yourself!
Requesting moderation
Aside from text and chat completion models, OpenAI provides models with other capabilities, including text moderation. OpenAI’s text moderation model is designed for evaluating prompts and responses to determine if they violate OpenAI’s usage policies, including inciting hate speech and promoting violence.
In this exercise, you’ll test out OpenAI’s moderation functionality on a sentence that may have been flagged as containing violent content using traditional word detection algorithms.
Instructions:
- Create a request to the Moderations endpoint to determine if the text,
"My favorite book is How to Kill a Mockingbird."violates OpenAI’s usage policies. - Print the category scores to see the results.
1
2
3
4
5
6
7
8
9
10
11
# Set your API key
# client = OpenAI(api_key=api_key) # creted at the top of the notebook
# Create a request to the Moderation endpoint
response = client.moderations.create(
model="text-moderation-latest",
input="My favorite book is How to Kill a Mockingbird."
)
# Print the category scores
response.results[0].category_scores.model_dump()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{'harassment': 1.4550790183420759e-05,
'harassment_threatening': 8.698739293322433e-06,
'hate': 5.186380440136418e-05,
'hate_threatening': 1.6861996243733302e-07,
'self_harm': 1.4029438943907735e-06,
'self_harm_instructions': 6.108327283982362e-07,
'self_harm_intent': 4.3481199440975615e-07,
'sexual': 6.508102160296403e-06,
'sexual_minors': 1.5272967175405938e-06,
'violence': 0.0020590308122336864,
'violence_graphic': 4.170028478256427e-05,
'self-harm': 1.4029438943907735e-06,
'sexual/minors': 1.5272967175405938e-06,
'hate/threatening': 1.6861996243733302e-07,
'violence/graphic': 4.170028478256427e-05,
'self-harm/intent': 4.3481199440975615e-07,
'self-harm/instructions': 6.108327283982362e-07,
'harassment/threatening': 8.698739293322433e-06}
You moderated magnificently! Having access to the category_scores means that you can set your own thresholds for flagging content.
Examining moderation category scores
The same request you created in the last exercise to the Moderation endpoint has been run again, sending the sentence "My favorite book is How to Kill a Mockingbird." to the model. The response from the API has been printed for you, and is available as response.
What is the correct interpretation of the category_scores here?
Answer:
- The model believes that there are no violations, as all categories are close to
0.
Fantastic work! Applications built on top of the OpenAI often contain multiple moderation steps to ensure that users cannot send inappropriate content to the model and to mitigate the risk of surfacing inappropriate content to users.
Speech-to-Text Transcription with Whisper
Speech-to-Text Transcription with Whisper: Welcome back! We’re now going to move away from OpenAI’s text models to take a look at the functionality of their audio models.
- OpenAI’s Whisper: OpenAI’s Whisper model has speech-to-text capabilities that can be used to create audio transcripts or translate audio from one language into an English transcript. The model supports many of the most common audio file formats, but does place a limit on the size of the audio file. Whisper has potential applications in automating business meeting transcripts and in accessibility features like caption generation. In this video, we’ll discuss creating transcription.
- Speech-to-text capabilities:
- Transcribe audio
- Translate and transcribe audio into English
- Supports
mp3,mp4,mpeg,mpga,m4a,wav, andwebm(25 MB limit) - Meeting transcripts
- Video captions
- Loading audio files: Let’s use Whisper to transcribe a meeting recording stored in an MP3 audio file. The first thing we need to do is to load the file into our Python environment. There are lots of Python libraries out there for working with audio files, but we’ll be using the Python open function here. The open function takes two arguments: the first is the file to be opened, and the second indicates the mode with which the file should be opened. Different modes support reading and writing to virtually any file type. The “rb” here stands for read binary - all this means is that we’re opening a file that is stored in a binary format, which is typical for non-text files like audio, video, and images. If the audio file is found in a different directory to the Python script or notebook we’re working in, we also need to prepend the file name with its path. This audio file can now be used like any other Python variable.
1
2
3
4
5
# Example: transcribe meeting_recording_20230602.mp3
audio_file = open("meeting_recording_20230602.mp3", "rb")
# If the file is located in a different directory
audio_file = open("path/to/file/meeting_recording_20230602.mp3", "rb")
- Making a request: Requests to the Whisper model are sent to the Audio endpoint of the API. To create a transcribe request to this endpoint, we call the create method on client.audio.transcriptions. Inside, we specify the audio model to use and the audio file to transcribe. Let’s print the response to see what’s returned. Like the other endpoints, we receive an object with attributes; but fortunately for transcriptions, there’s on a single attribute to handle.
- Audio Endpoint
1
2
3
4
5
6
audio_file= open("meeting_recording_20230602.mp3", "rb")
response = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
print(response)
[out]:
Transcription(text="Welcome everyone to the June product monthly. We'll get started in...)
- The transcript: We can access the transcript text using the text attribute. There we have it! The model did a solid job of transcribing the audio, but note that its performance may fluctuate with changes in audio quality or different accents. Sensitive or confidential audio should also not be sent to the model.
1
2
3
4
print(response.text)
[out]:
Welcome everyone to the June product monthly. We'll get started in just a minute. Alright, let's get started. Today's agenda will start with a spotlight from Chris on the new mobile user onboarding flow, then we'll review how we're tracking on our quarterly targets, and finally, we'll finish with another spotlight from Katie who will discuss the upcoming branding updates...
- Don’t use sensitive or confidential recordings
- Transcribing non-English languages: Due to the Whisper model being trained on audio from non-English languages, it can also transcribe audio from many other languages with good results. The process for transcribing non-English audio is exactly the same: we open the audio file, make a transcription request to the Audio endpoint, and extract the text from the response.
open()audio file- Make a transcriptions request to the Audio endpoint
- Extract text from the response
Creating a podcast transcript
The OpenAI API Audio endpoint provides access to the Whisper model, which can be used for speech-to-text transcription and translation. In this exercise, you’ll create a transcript from a DataFramed podcast episode with OpenAI Developer, Logan Kilpatrick.
If you’d like to hear more from Logan, check out the full ChatGPT and the OpenAI Developer Ecosystem podcast episode.
Instructions:
- Open the
openai-audio.mp3file. - Create a transcription request to the Audio endpoint.
- Extract and print the transcript text from the
response.
1
2
3
4
5
6
7
8
# Open the audio file
audio_file = open(r".\data\2024-01-29_working_with_the_openai_api\audio-logan-advocate-openai.mp3", "rb")
# Create a transcription request to the Audio endpoint
response = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
# Extract and print the transcript text from the response
print(response.text)
1
Hi there, Logan, thank you for joining us on the show today. Thanks for having me. I'm super excited about this. Brilliant. We're going to dive right in, and I think ChatGPT is maybe the most famous AI product that you have at OpenAI, but I'd just like to get an overview of what all the other AIs that are available are. So I think two and a half years ago, OpenAI released the API that we still have available today, which is essentially our giving people access to these models. And for a lot of people, giving people access to the model that powers ChatGPT, which is our consumer-facing first-party application, which essentially just, in very simple terms, puts a nice UI on top of what was already available through our API for the last two and a half years. So it's sort of democratizing the access to this technology through our API. If you want to just play around with it, as an end user, we have ChatGPT available to the world as well.
Audibly awesome! Using an OpenAI model to transcribe a recording of an OpenAI developer talking about OpenAI is mind-bending stuff, but transcriptions don’t just stop with English audio. In the next exercise, you’ll apply your skills to obtain transcripts from another language.
Transcribing a non-English language
The Whisper model can not only transcribe English language, but also performs well on speech in many other languages.
In this exercise, you’ll create a transcript from audio.m4a, which contains speech in Portuguese.
Instructions:
- Open the
audio.m4afile. - Create a request to the Audio endpoint to transcribe
audio.m4a.
1
2
3
4
5
6
7
8
# open the portuguese audio file
audio_file = open(r".\data\2024-01-29_working_with_the_openai_api\audio-portuguese.m4a", "rb")
# Create a request to the Audio endpoint to transcribe the portuguese audio.m4a
response = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
# Print the transcript text from the response
print(response.text)
1
Olá, o meu nome é Eduardo, sou CTO no Datacamp. Espero que esteja a gostar deste curso que o James e eu criamos para você. Esta API permite enviar um áudio e trazer para inglês. O áudio original está em português.
Awesome work! Being able to transcribe speech into the native language is very useful; in the next video, you’ll see how the Whisper model can also translate it into English.
Speech Translation with Whisper
Speech Translation with Whisper: In this video, we’ll discuss Whisper’s translation capabilities. Let’s dive right in!
- Whisper’s translation capabilities: The Whisper model not only has the ability to transcribe audio into the language it’s in, but also translate and transcribe audio in one go. This is currently limited to an English transcript, so we can translate and transcribe German into English, but not German into French. Like with its transcription functionality, Whisper can translate audio from most common audio file types up to a particular size limit.
- Translate and transcribe audio
- Currently limited to English transcripts
- Supports
mp3,mp4,mpeg,mpga,m4a,wav, andwebm(25 MB limit)
- Translating audio: The process for translating and transcribing audio is almost identical to normal transcription, with just one change. We open the non-English audio to translate and transcribe, which in this case is an m4a file. This is where the change comes in - instead of using the create method on client.audio.transcriptions, we call it on client.audio.translations. The translated transcription can be extracted using the text attribute. Looking at the transcript, we can see that it wasn’t perfect - making two spelling errors. The performance of Whisper can vary wildly depending on audio quality, the language the audio is recorded in, and the model’s knowledge of the subject matter. Before creating a full-fledged application on this model, you’ll need to test that the model’s performance is sufficiently good for the particular use case. Let’s see how we can give Whisper a helping hand here.
1
2
3
4
5
6
audio_file = open("non_english_audio.m4a", "rb")
response = client.audio.translations.create(model="whisper-1", file=audio_file)
print(response.text)
[out]:
The search volume for keywords like A I has increased rapidly since the launch of Cha GTP.
- Performance can vary wildly, depending on:
- Audio quality
- Audio language
- Model’s knowledge of the subject matter
- Bringing prompts into the mix: When we send our audio to the Whisper model, we can also provide an optional prompt. This prompt can be used to improve the quality of the response by providing an example of how we want the transcript to be styled. For example, if we want the transcript to retain filler words from the audio, like ummms and uhhhhs, we can provide the following prompt along with the audio. If we know broadly what the topic of the audio is about, we can also this context as a prompt to help the model narrow-down the correct words. Here’s an example of a prompt to give the model more context. Transcriptions also supports prompts that can be used in a very similar way. Let’s adapt our last request with a prompt to try and fix the spelling errors outputted by the model.
- Can provide prompt to the model (optional)
- Improve response quality by:
- Providing an example of desired style
- Provide context on transcript context
1
2
3
4
5
# Example: Retaining filler words
prompt="Ok, ummm... this is what we should do, like, to uhhh... increase revenue."
# Example: Provide context
prompt="A discussion on how to increase revenue."
- Adding in a prompt: Let’s assume that we know the audio discusses AI trends and ChatGPT; we can define a prompt with this context, and pass it to the prompt argument. Printing the response, shows, that with a little extra context, the model was able to accurately determine the correct spelling and style of the words. In this example, the original response was already pretty close to what we wanted, but for other cases, it’s possible to see quite dramatic improvements using prompts.
1
2
3
4
5
6
7
8
9
audio_file = open("non_english_audio.m4a", "rb")
prompt = "The transcript is about AI trends and ChatGPT."
response = client.audio.translations.create(model="whisper-1",
file=audio_file,
prompt=prompt)
print(response.text)
[out]:
The search volume for keywords like AI has increased rapidly since the launch of ChatGPT.
Translating Portuguese
Whisper can not only transcribe audio into its native language but also supports translation capabilities for creating English transcriptions.
In this exercise, you’ll return to the Portuguese audio, but this time, you’ll translate it into English!
Instructions:
- Open the
audio.m4afile. - Create a translation request to the Audio endpoint.
- Extract and print the translated text from the response.
1
2
3
4
5
6
7
8
# Open the audio.m4a file
audio_file = open(r".\data\2024-01-29_working_with_the_openai_api\audio-portuguese.m4a", "rb")
# Create a translation from the Portuguese audio file to English
response = client.audio.translations.create(model="whisper-1", file=audio_file)
# Extract and print the translated text
print(response.text)
1
Hello, my name is Eduardo, I am a CTO at Datacamp. I hope you are enjoying this course that James and I have created for you. This API allows you to send an audio and bring it to English. The original audio is in Portuguese.
Look at that—that’s a pretty good translation! The model may not always be perfect, outputting minor wording differences or imperfect grammar, but it performs well for the most widely-used languages.
Translating with prompts
The quality of Whisper’s translation can vary depending on the language spoken, the audio quality, and the model’s awareness of the subject matter. If you have any extra context about what is being spoken about, you can send it along with the audio to the model to give it a helping hand.
You’ve been provided with with an audio file, audio.wav; you’re not sure what language is spoken in it, but you do know it relates to a recent World Bank report. Because you don’t know how well the model will perform on this unknown language, you opt to send the model this extra context to steer it in the right direction.
Instructions:
- Open the
audio.wavfile. - Write a prompt that informs the model that the audio relates to a recent World Bank report, which will help the model produce an accurate translation.
- Create a request to the Audio endpoint to transcribe
audio.wavusing yourprompt.
1
2
3
4
5
6
7
8
9
10
11
# Open the audio.wav file
audio_file = open(r".\data\2024-01-29_working_with_the_openai_api\mandarin-full.wav", "rb")
# Write a prompt to inform the model that the audio relates to a recent World Bank report
prompt = "The audio relates to a recent World Bank report."
# Create a request to the Audio endpoint to transcribe audio.wav using your prompt
response = client.audio.translations.create(model="whisper-1", file=audio_file, prompt=prompt)
# Print the translated text from the response
print(response.text)
1
The World Bank said in its latest economic outlook report that the global economy is in a dangerous state. As interest rates rise, consumer spending and corporate investment will slow down, economic activities will be impacted, and the vulnerability of low-income countries will be exposed. Global economic growth will be significantly slowed down, and the stability of the financial system will be threatened.
Well done! The mystery language here is actually Mandarin Chinese, so you’ve seen that the model performs well for English, Portuguese, and Mandarin—three pretty linguistically different languages! In the next video, you’ll learn to combine models together, so you’ll use the output from one model as the input to another. Stay tuned!
Combining Models
- Combining models: Welcome back! In this video, we’ll take it up a gear and look at how we can combine models together. So far, when we’ve been using functionality from the OpenAI API, we’ve completed a task by passing an input to the model and receiving an output. This got us pretty far, from simple question answering to multi-turn conversations and audio translation. But what if we could do more with the model’s output. Enter model chaining. Chaining is when models are combined by feeding the output from one model directly into another model as an input. We can chain multiple calls to the same model together or use different models. If we chain two text models together, we can ask the model to perform a task in one call to the API and send it back with an additional instruction. For example, let’s say we draft an email template for a customer, and we want to validate that the template follows some guidelines, we can send it back to the model with an instruction to check whether the guidelines are followed. We can also combine two different types of models, say the Whisper model into a text model, to perform tasks like summarizing discussion points and next steps from a meeting recording. Let’s have a go at chaining Whisper with a chat model.

- Chaining: Feeding output from one model into another
- Can use the same model multiple times
- Example: validating original response
- Or different models
- Example: summarizing meeting recordings
- Example: Extracting meeting attendees: Let’s use Whisper to extract the attendees from a meeting recording, where we know it starts with introductions from each of the attendees. We start by opening the audio file and assigning it audio_file. Next, we send the audio to the Whisper model and request a transcript with the transcribe method. To extract the transcript from the response, we extract the value from the text key. Now that we have the meeting transcript, we can use it to create a prompt for the chat model. The prompt starts with an instruction to extract the attendee names from the start of the transcript, then we append the transcript to the end. We’re now ready to send the prompt to the chat model! We create a request to the Chat Completions endpoint using the create method. Inside, we specify the model to use and the messages to send, which is just the prompt in this case. Finally, we extract the response from the chat model. Extracting meeting attendees: And there we have it! As with all of these models, there’s no guarantee that the models will be 100% accurate - Whisper could make a mistake in the transcript or the chat model may summarize incorrectly. It’s important that any application of these models is well-tested, iterating on the prompts if necessary, to understand its performance thresholds. Additionally, usage should be restricted to only non-sensitive data, as we may risk breaching data governance laws by unjustly exposing employee or customer data.
1
2
3
4
5
6
7
8
9
10
11
audio_file = open("meeting_recording_20230608.mp4", "rb")
audio_response = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
transcript = audio_response.text
prompt = "Extract the attendee names from the start of this meeting transcript: " + transcript
chat_response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}])
print(chat_response.choices[0].message.content)
[out]:
The meeting attendees were Otis, Paul, Elaine, Nicola, Alan, and Imran.
- Note:
- No guarantees on model performance
- Ensure that applications are well-tested
- Usage should be restricted to non-sensitive data
Identifying audio language
You’ve learned that you’re not only limited to creating a single request, and that you can actually feed the output of one model as an input to another! This is called chaining, and it opens to the doors to more complex, multi-modal use cases.
In this exercise, you’ll practice model chaining to identify the language used in an audio file. You’ll do this by bringing together OpenAI’s audio transcription functionality and its text models with only a few lines of code.
Instructions:
- Open the
arne-german-automotive-forecast.wavfile and assign toaudio_file. - Create a transcript from
audio_fileand assign totranscript. - Prompt a text model using the text from transcript to discover the language used in a
arne-german-automotive-forecast.wav; print the model’s response.
1
2
3
4
5
6
7
8
9
10
11
# Open the arne-german-automotive-forecast.wav file
audio_file = open(r".\data\2024-01-29_working_with_the_openai_api\arne-german-automotive-forecast.wav", "rb")
# Create a transcription request using audio_file
audio_response = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
# Create a request to the API to identify the language spoken
prompt = "Identify the language spoken in the audio file."
chat_response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt + audio_response.text}])
1
2
3
4
# print the audio response
print(audio_response.text)
# Print the model's response
print(chat_response.choices[0].message.content)
1
2
Hallo, ich arbeite für die Automobilindustrie und benötige eine Vorhersage für die zukünftige Nachfrage nach Elektroautomobilen. Daher bin ich jetzt bei DataCamp und ich bin schon sehr gespannt, mehr über maschinell zu lernen und Vorhersagen zu erfahren.
German
Chaining models in this way opens the door to even more use cases for integrating OpenAI’s models into business processes and workflows. In the next exercise, you’ll chain models together to create meeting summaries from recordings—imagine all of the time that can be saved here!
Creating meeting summaries
Time for business! One time-consuming task that many find themselves doing day-to-day is taking meeting notes to summarize attendees, discussion points, next steps, etc.
In this exercise, you’ll use AI to augment this task to not only save a substantial amount of time, but also to empower attendees to focus on the discussion rather than administrative tasks. You’ve been provided with a recording from DataCamp’s Q2 Roadmap webinar, which summarizes what DataCamp will be releasing during that quarter. You’ll chain the Whisper model with a text or chat model to discover which courses will be launched in Q2.
Instructions:
- Open the
datacamp-q2-roadmap.mp3file and assign toaudio_file. - Create a transcript from
audio_fileand assign totranscript. - Prompt a text model using the text from
transcriptand summarize it into concise bullet points.
1
2
3
4
5
6
7
8
9
10
11
# Open the datacamp-q2-roadmap.mp3 file
audio_file = open(r".\data\2024-01-29_working_with_the_openai_api\datacamp-q2-roadmap-short.mp3", "rb")
# Create a transcription request using audio_file
audio_response = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
# Create a request to the API to summarize the transcript into bullet points
prompt = "Summarize this in two bullet points: " + audio_response.text
chat_response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}])
1
2
3
4
# Print the audio response
print(audio_response.text)
# Print the model's response
print(chat_response.choices[0].message.content)
1
2
3
Moving to the more technical courses, so working with the OpenAI API courses, Python course. So this is gonna be how do I do programming against GPT and Whisper, so things like, oh, how do I transcribe meeting notes, that sort of thing, using Python code. Understanding Artificial Intelligence is, again, aimed at a less technical audience, so this is gonna give you a background of what is Artificial Intelligence beyond just these fancy new models, because it really is a very broad category of study. And finally, we have Artificial Intelligence Ethics. So there are a lot of ways you can do AI wrong. If you do it wrong, this can seriously harm your business or organization, so you need to make sure you do it right. And actually, maybe even worse, beyond harming your business or organization, it can also provide problems to your customers, and nobody wants that. All right, so definitely, AI Ethics is worth taking, and I would encourage you to look up, in fact, all of these courses, see what's appropriate for you or your colleagues. We have quite a few data literacy courses coming out as well, and I wanted to highlight this particular one, because it's something that's been asked for for quite a long time. So one problem that a lot of people who don't have a data background have is when they're trying to get help from a data analyst or a data scientist or someone else who's technical, they don't know what questions to ask in order to get that help effectively. And quite often, there's a big communication barrier between people with and without a data background. And so forming analytical questions teaches you how to ask good questions, really gonna help that communication between technical and non-technical people. In fact, even if you are technical already, like you've got this data background, it's maybe worth taking this course just to see how people get it wrong when they're asking you things. So communication is always the key to doing better data science. We do a lot of webinars, a lot of podcasts, and we ask all the experts, well, how do you do data science better? But communication is always one of the top answers. So really, this is like a hugely important course. Everyone needs to take this. Yeah, this one is already live. I think Rhys can perhaps post a link to this in the chat. Yeah, please do check this course, it's well worthwhile.
- Moving to more technical courses including OpenAI API and Python courses for programming against GPT and Whisper
- Importance of AI Ethics in avoiding harm to business, organization, and customers, and the value of forming analytical questions for effective communication between technical and non-technical individuals in data science.
Conclusion
- Chapter 1: Started to learn about the OpenAI API - what it was used for, how to create an API key for authentication, and how to make requests to the API via the Completions endpoint. You also learned about creating and managing organizations, which you can use to mitigate rate limit risks and better manage usage and expenditure.
- What the OpenAI API is used for
- How to create an API key
- How to create requests to the Completions endpoint
- Creating and managing organizations
- Chapter 2: Turned text completions up to the max, and applied OpenAI’s models to solve a range of tasks, including question answering, text transformation, content generation, sentiment analysis, and categorization. You even learned how to control the model’s behavior by tweaking the max_tokens and temperature parameters. From there, you unlocked the potential for multi-turn conversations using the Chat Completions endpoint, and created your very first AI chatbot.
1
2
3
4
5
6
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="When was OpenAI founded?",
max_tokens=20,
temperature=0.5
)
- Solved different tasks with text completions, including:
- Q&A
- Text transformation
- Content generation
- Sentiment analysis
- Categorization
max_tokensandtemperature- Multi-turn conversation with Chat Completions
- Chapter 3: Explored OpenAI’s moderation and audio functionality, and used these models to detect inappropriate content, and translate and transcribe audio recordings. Finally, you brought everything together by chaining models together to start automating more complex tasks like creating meeting summaries from recordings.
- Moderation
- Detect inappropriate content
- Audio
- Translate
- Transcribe
- Chaining
- Automating complex tasks
- Moderation
- What next?: Although AI application development is a relatively new area, DataCamp already has additional courses that will help you create more impressive and diverse applications, so feel free to check them out!
- AI application development:
- ChatGPT Prompt Engineering for Developers
- Introduction to Embeddings with the OpenAI API
- Developing LLM Applications with LangChain (coming soon!)
- Working with Hugging Face (coming soon!)
- Apply your learning in projects:
- AI application development:
Certificate
