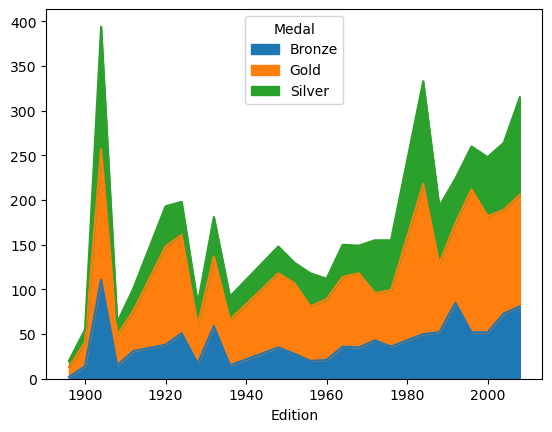
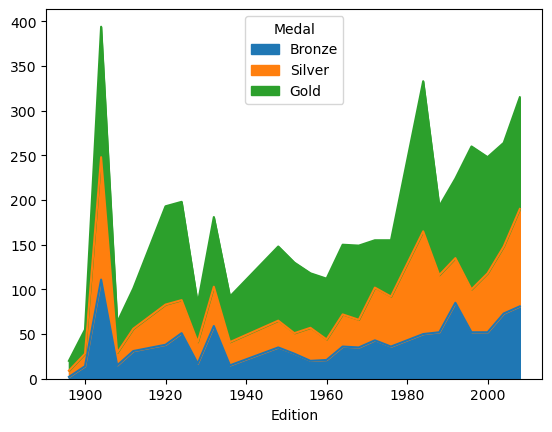
1
2
3
4
5
6
| import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from numpy import NaN
from scipy.stats import zscore
import os
|
Tested with the following package versions
1
2
3
4
| print('Pandas version:', pd.__version__)
print('Numpy version:', np.__version__)
print('Matplotlib version:', plt.matplotlib.__version__)
print('Scipy version:', scipy.__version__) # import scipy
|
Pandas version: 2.2.1
Numpy version: 1.26.4
Matplotlib version: 3.8.1
Scipy version: 1.12.0
Set Display Options
1
2
3
| pd.set_option('display.max_columns', 50)
pd.set_option('display.max_rows', 100)
pd.set_option('display.expand_frame_repr', True)
|
Data Files Location
Data File Objects
1
2
3
4
5
6
7
8
9
10
11
| election_penn = 'data/manipulating-dataframes-with-pandas/2012_US_election_results_(Pennsylvania).csv'
gapminder_data = 'data/manipulating-dataframes-with-pandas/gapminder.csv'
medals_data = 'data/manipulating-dataframes-with-pandas/olympic_medals.csv'
weather_data = 'data/manipulating-dataframes-with-pandas/Pittsburgh_weather_data.csv'
sales_data = 'data/manipulating-dataframes-with-pandas/sales.csv'
sales2_data = 'data/manipulating-dataframes-with-pandas/sales2.csv'
sales_feb = 'data/manipulating-dataframes-with-pandas/sales-feb-2015.csv'
titanic_data = 'data/manipulating-dataframes-with-pandas/titanics.csv'
users_data = 'data/manipulating-dataframes-with-pandas/users.csv'
massachusetts_labor = 'data/manipulating-dataframes-with-pandas/LURReport.csv'
auto_mpg = 'data/manipulating-dataframes-with-pandas/auto-mpg.csv'
|
Manipulating DataFrames with pandas
Course Description
In this course, you’ll learn how to leverage pandas’ extremely powerful data manipulation engine to get the most out of your data. It is important to be able to extract, filter, and transform data from DataFrames in order to drill into the data that really matters. The pandas library has many techniques that make this process efficient and intuitive. You will learn how to tidy, rearrange, and restructure your data by pivoting or melting and stacking or unstacking DataFrames. These are all fundamental next steps on the road to becoming a well-rounded Data Scientist, and you will have the chance to apply all the concepts you learn to real-world datasets.
What You’ll Learn
- Extracting, filtering, and transforming data from DataFrames
- Advanced indexing with multiple levels
- Tidying, rearranging and restructuring your data
- Pivoting, melting, and stacking DataFrames
- Identifying and spli!ing DataFrames by groups
In this chapter, you will learn all about how to index, slice, filter, and transform DataFrames, using a variety of datasets, ranging from 2012 US election data for the state of Pennsylvania to Pittsburgh weather data.
Indexing DataFrames
A simple DataFrame
1
2
| df = pd.read_csv(sales_data, index_col='month')
df
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
| May | 132 | NaN | 52 |
|---|
| Jun | 205 | 60.0 | 55 |
|---|
Indexing using square brackets
Using column attribute and row label
Accessors
- A more efficient and more programmatically reusable method of accessing data in a DataFrame is by using accessors
- .loc - accesses using lables
- .iloc - accesses using index positions
- Both accessors use left bracket, row specifier, comma, column specifier, right bracket as syntax
Using the .loc accessor
Using the .iloc accessor
Selecting only some columns
- When using bracket-indexing without the .loc or .iloc accessors, the result returned can be an individual value, Pandas Series, or Pandas DataFrame.
- To ensure the return value is a DataFrame, use a nested list within square brackets
1
2
| df_new = df[['salt','eggs']]
df_new
|
| salt | eggs |
|---|
| month | | |
|---|
| Jan | 12.0 | 47 |
|---|
| Feb | 50.0 | 110 |
|---|
| Mar | 89.0 | 221 |
|---|
| Apr | 87.0 | 77 |
|---|
| May | NaN | 132 |
|---|
| Jun | 60.0 | 205 |
|---|
Exercises
Index ordering
In this exercise, the DataFrame election is provided for you. It contains the 2012 US election results for the state of Pennsylvania with county names as row indices. Your job is to select ‘Bedford’ county and the ‘winner’ column. Which method is the preferred way?
1
2
| election = pd.read_csv(election_penn, index_col='county')
election.head()
|
| state | total | Obama | Romney | winner | voters | turnout | margin |
|---|
| county | | | | | | | | |
|---|
| Adams | PA | 41973 | 35.482334 | 63.112001 | Romney | 61156 | 68.632677 | 27.629667 |
|---|
| Allegheny | PA | 614671 | 56.640219 | 42.185820 | Obama | 924351 | 66.497575 | 14.454399 |
|---|
| Armstrong | PA | 28322 | 30.696985 | 67.901278 | Romney | 42147 | 67.198140 | 37.204293 |
|---|
| Beaver | PA | 80015 | 46.032619 | 52.637630 | Romney | 115157 | 69.483401 | 6.605012 |
|---|
| Bedford | PA | 21444 | 22.057452 | 76.986570 | Romney | 32189 | 66.619031 | 54.929118 |
|---|
1
| election.loc['Bedford', 'winner']
|
Positional and labeled indexing
Given a pair of label-based indices, sometimes it’s necessary to find the corresponding positions. In this exercise, you will use the Pennsylvania election results again. The DataFrame is provided for you as election.
Find x and y such that election.iloc[x, y] == election.loc[‘Bedford’, ‘winner’]. That is, what is the row position of ‘Bedford’, and the column position of ‘winner’? Remember that the first position in Python is 0, not 1!
To answer this question, first explore the DataFrame using election.head() in the IPython Shell and inspect it with your eyes.
Instructions
- Explore the DataFrame in the IPython Shell using election.head().
- Assign the row position of election.loc[‘Bedford’] to x.
- Assign the column position of election[‘winner’] to y.
- Hit ‘Submit Answer’ to print the boolean equivalence of the .loc and .iloc selections.
1
2
3
4
5
6
7
8
| # Assign the row position of election.loc['Bedford']: x
x = 4
# Assign the column position of election['winner']: y
y = 4
# Print the boolean equivalence
print(election.iloc[x, y] == election.loc['Bedford', 'winner'])
|
Depending on the situation, you may wish to use .iloc[] over .loc[], and vice versa. The important thing to realize is you can achieve the exact same results using either approach.
Indexing and column rearrangement
There are circumstances in which it’s useful to modify the order of your DataFrame columns. We do that now by extracting just two columns from the Pennsylvania election results DataFrame.
Your job is to read the CSV file and set the index to ‘county’. You’ll then assign a new DataFrame by selecting the list of columns [‘winner’, ‘total’, ‘voters’]. The CSV file is provided to you in the variable filename.
Instructions
- Import pandas as pd.
- Read in filename using pd.read_csv() and set the index to ‘county’ by specifying the index_col parameter.
- Create a separate DataFrame results with the columns [‘winner’, ‘total’, ‘voters’].
- Print the output using results.head(). This has been done for you, so hit ‘Submit Answer’ to see the new DataFrame!
1
2
3
4
5
6
7
8
| # Read in filename and set the index: election
election = pd.read_csv(election_penn, index_col='county')
# Create a separate dataframe with the columns ['winner', 'total', 'voters']: results
results = election[['winner', 'total', 'voters']]
# Print the output of results.head(['winner', 'total', 'voters'])
print(results.head())
|
1
2
3
4
5
6
7
| winner total voters
county
Adams Romney 41973 61156
Allegheny Obama 614671 924351
Armstrong Romney 28322 42147
Beaver Romney 80015 115157
Bedford Romney 21444 32189
|
The original election DataFrame had 6 columns, but as you can see, your results DataFrame now has just the 3 columns: ‘winner’, ‘total’, and ‘voters’.
Slicing DataFrames
sales DataFrame
1
2
| df = pd.read_csv(sales_data, index_col='month')
df
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
| May | 132 | NaN | 52 |
|---|
| Jun | 205 | 60.0 | 55 |
|---|
Selecting a column (i.e., Series)
1
2
3
4
5
6
7
8
| month
Jan 47
Feb 110
Mar 221
Apr 77
May 132
Jun 205
Name: eggs, dtype: int64
|
1
| pandas.core.series.Series
|
Slicing and indexing a Series
1
| df['eggs'].iloc[1:4] # Part of the eggs column
|
1
2
3
4
5
| month
Feb 110
Mar 221
Apr 77
Name: eggs, dtype: int64
|
1
| df['eggs'].iloc[4] # The value associated with May
|
Using .loc[] (1)
1
| df.loc[:, 'eggs':'salt'] # All rows, some columns
|
| eggs | salt |
|---|
| month | | |
|---|
| Jan | 47 | 12.0 |
|---|
| Feb | 110 | 50.0 |
|---|
| Mar | 221 | 89.0 |
|---|
| Apr | 77 | 87.0 |
|---|
| May | 132 | NaN |
|---|
| Jun | 205 | 60.0 |
|---|
Using .loc[] (2)
1
| df.loc['Jan':'Apr',:] # Some rows, all columns
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
Using .loc[] (3)
1
| df.loc['Mar':'May', 'salt':'spam']
|
| salt | spam |
|---|
| month | | |
|---|
| Mar | 89.0 | 72 |
|---|
| Apr | 87.0 | 20 |
|---|
| May | NaN | 52 |
|---|
Using .iloc[]
1
| df.iloc[2:5, 1:] # A block from middle of the DataFrame
|
| salt | spam |
|---|
| month | | |
|---|
| Mar | 89.0 | 72 |
|---|
| Apr | 87.0 | 20 |
|---|
| May | NaN | 52 |
|---|
Using lists rather than slices (1)
1
| df.loc['Jan':'May', ['eggs', 'spam']]
|
| eggs | spam |
|---|
| month | | |
|---|
| Jan | 47 | 17 |
|---|
| Feb | 110 | 31 |
|---|
| Mar | 221 | 72 |
|---|
| Apr | 77 | 20 |
|---|
| May | 132 | 52 |
|---|
Using lists rather than slices (2)####
| eggs | salt |
|---|
| month | | |
|---|
| Jan | 47 | 12.0 |
|---|
| May | 132 | NaN |
|---|
| Jun | 205 | 60.0 |
|---|
Series versus 1-column DataFrame
1
2
| # A Series by column name
df['eggs']
|
1
2
3
4
5
6
7
8
| month
Jan 47
Feb 110
Mar 221
Apr 77
May 132
Jun 205
Name: eggs, dtype: int64
|
1
| pandas.core.series.Series
|
1
2
| # A DataFrame w/ single column
df[['eggs']]
|
| eggs |
|---|
| month | |
|---|
| Jan | 47 |
|---|
| Feb | 110 |
|---|
| Mar | 221 |
|---|
| Apr | 77 |
|---|
| May | 132 |
|---|
| Jun | 205 |
|---|
1
| pandas.core.frame.DataFrame
|
Exercises
Slicing rows
The Pennsylvania US election results data set that you have been using so far is ordered by county name. This means that county names can be sliced alphabetically. In this exercise, you’re going to perform slicing on the county names of the election DataFrame from the previous exercises, which has been pre-loaded for you.
Instructions
- Slice the row labels ‘Perry’ to ‘Potter’ and assign the output to p_counties.
- Print the p_counties DataFrame. This has been done for you.
- Slice the row labels ‘Potter’ to ‘Perry’ in reverse order. To do this for hypothetical row labels ‘a’ and ‘b’, you could use a stepsize of -1 like so: df.loc[‘b’:’a’:-1].
- Print the p_counties_rev DataFrame. This has also been done for you, so hit ‘Submit Answer’ to see the result of your slicing!
1
2
3
4
5
6
7
8
9
10
11
| # Slice the row labels 'Perry' to 'Potter': p_counties
p_counties = election.loc['Perry':'Potter']
# Print the p_counties DataFrame
display(p_counties)
# Slice the row labels 'Potter' to 'Perry' in reverse order: p_counties_rev
p_counties_rev = election.loc['Potter':'Perry':-1]
# Print the p_counties_rev DataFrame
p_counties_rev
|
| state | total | Obama | Romney | winner | voters | turnout | margin |
|---|
| county | | | | | | | | |
|---|
| Perry | PA | 18240 | 29.769737 | 68.591009 | Romney | 27245 | 66.948064 | 38.821272 |
|---|
| Philadelphia | PA | 653598 | 85.224251 | 14.051451 | Obama | 1099197 | 59.461407 | 71.172800 |
|---|
| Pike | PA | 23164 | 43.904334 | 54.882576 | Romney | 41840 | 55.363289 | 10.978242 |
|---|
| Potter | PA | 7205 | 26.259542 | 72.158223 | Romney | 10913 | 66.022175 | 45.898681 |
|---|
| state | total | Obama | Romney | winner | voters | turnout | margin |
|---|
| county | | | | | | | | |
|---|
| Potter | PA | 7205 | 26.259542 | 72.158223 | Romney | 10913 | 66.022175 | 45.898681 |
|---|
| Pike | PA | 23164 | 43.904334 | 54.882576 | Romney | 41840 | 55.363289 | 10.978242 |
|---|
| Philadelphia | PA | 653598 | 85.224251 | 14.051451 | Obama | 1099197 | 59.461407 | 71.172800 |
|---|
| Perry | PA | 18240 | 29.769737 | 68.591009 | Romney | 27245 | 66.948064 | 38.821272 |
|---|
Slicing columns
Similar to row slicing, columns can be sliced by value. In this exercise, your job is to slice column names from the Pennsylvania election results DataFrame using .loc[].
It has been pre-loaded for you as election, with the index set to ‘county’.
Instructions
- Slice the columns from the starting column to ‘Obama’ and assign the result to left_columns
- Slice the columns from ‘Obama’ to ‘winner’ and assign the result to middle_columns
- Slice the columns from ‘Romney’ to the end and assign the result to right_columns
- The code to print the first 5 rows of left_columns, middle_columns, and right_columns has been written, so hit ‘Submit Answer’ to see the results!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # Slice the columns from the starting column to 'Obama': left_columns
left_columns = election.loc[:, :'Obama']
# Print the output of left_columns.head()
print('Left Columns: \n', left_columns.head())
# Slice the columns from 'Obama' to 'winner': middle_columns
middle_columns = election.loc[:, 'Obama':'winner']
# Print the output of middle_columns.head()
print('\nMiddle Columns: \n', middle_columns.head())
# Slice the columns from 'Romney' to the end: 'right_columns'
right_columns = election.loc[:, 'Romney':]
# Print the output of right_columns.head()
print('\nRight Columns: \n', right_columns.head())
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| Left Columns:
state total Obama
county
Adams PA 41973 35.482334
Allegheny PA 614671 56.640219
Armstrong PA 28322 30.696985
Beaver PA 80015 46.032619
Bedford PA 21444 22.057452
Middle Columns:
Obama Romney winner
county
Adams 35.482334 63.112001 Romney
Allegheny 56.640219 42.185820 Obama
Armstrong 30.696985 67.901278 Romney
Beaver 46.032619 52.637630 Romney
Bedford 22.057452 76.986570 Romney
Right Columns:
Romney winner voters turnout margin
county
Adams 63.112001 Romney 61156 68.632677 27.629667
Allegheny 42.185820 Obama 924351 66.497575 14.454399
Armstrong 67.901278 Romney 42147 67.198140 37.204293
Beaver 52.637630 Romney 115157 69.483401 6.605012
Bedford 76.986570 Romney 32189 66.619031 54.929118
|
Subselecting DataFrames with lists
You can use lists to select specific row and column labels with the .loc[] accessor. In this exercise, your job is to select the counties [‘Philadelphia’, ‘Centre’, ‘Fulton’] and the columns [‘winner’,’Obama’,’Romney’] from the election DataFrame, which has been pre-loaded for you with the index set to ‘county’.
Instructions
- Create the list of row labels [‘Philadelphia’, ‘Centre’, ‘Fulton’] and assign it to rows.
- Create the list of column labels [‘winner’, ‘Obama’, ‘Romney’] and assign it to cols.
- Create a new DataFrame by selecting with rows and cols in .loc[] and assign it to three_counties.
- Print the three_counties DataFrame. This has been done for you, so hit ‘Submit Answer` to see your new DataFrame.
1
2
3
4
5
6
7
8
9
10
11
| # Create the list of row labels: rows
rows = ['Philadelphia', 'Centre', 'Fulton']
# Create the list of column labels: cols
cols = ['winner', 'Obama', 'Romney']
# Create the new DataFrame: three_counties
three_counties = election.loc[rows, cols]
# Print the three_counties DataFrame
print(three_counties)
|
1
2
3
4
5
| winner Obama Romney
county
Philadelphia Obama 85.224251 14.051451
Centre Romney 48.948416 48.977486
Fulton Romney 21.096291 77.748861
|
If you know exactly which rows and columns are of interest to you, this is a useful approach for subselecting DataFrames.
Filtering DataFrames
Data
1
2
| df = pd.read_csv(sales_data, index_col='month')
df
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
| May | 132 | NaN | 52 |
|---|
| Jun | 205 | 60.0 | 55 |
|---|
Creating a Boolean Series
1
2
3
4
5
6
7
8
| month
Jan False
Feb False
Mar True
Apr True
May False
Jun False
Name: salt, dtype: bool
|
Filtering with a Boolean Series
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
1
| enough_salt_sold = df.salt > 60
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
Combining filters
1
| df[(df.salt >= 50) & (df.eggs < 200)] # Both conditions
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
1
| df[(df.salt >= 50) | (df.eggs < 200)] # Either condition
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
| May | 132 | NaN | 52 |
|---|
| Jun | 205 | 60.0 | 55 |
|---|
DataFrames with zeros and NaNs
1
| df2['bacon'] = [0, 0, 50, 60, 70, 80]
|
| eggs | salt | spam | bacon |
|---|
| month | | | | |
|---|
| Jan | 47 | 12.0 | 17 | 0 |
|---|
| Feb | 110 | 50.0 | 31 | 0 |
|---|
| Mar | 221 | 89.0 | 72 | 50 |
|---|
| Apr | 77 | 87.0 | 20 | 60 |
|---|
| May | 132 | NaN | 52 | 70 |
|---|
| Jun | 205 | 60.0 | 55 | 80 |
|---|
Select columns with all nonzeros
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
| May | 132 | NaN | 52 |
|---|
| Jun | 205 | 60.0 | 55 |
|---|
Select columns with any nonzeros
| eggs | salt | spam | bacon |
|---|
| month | | | | |
|---|
| Jan | 47 | 12.0 | 17 | 0 |
|---|
| Feb | 110 | 50.0 | 31 | 0 |
|---|
| Mar | 221 | 89.0 | 72 | 50 |
|---|
| Apr | 77 | 87.0 | 20 | 60 |
|---|
| May | 132 | NaN | 52 | 70 |
|---|
| Jun | 205 | 60.0 | 55 | 80 |
|---|
Select columns with any NaNs
1
| df.loc[:, df.isnull().any()]
|
| salt |
|---|
| month | |
|---|
| Jan | 12.0 |
|---|
| Feb | 50.0 |
|---|
| Mar | 89.0 |
|---|
| Apr | 87.0 |
|---|
| May | NaN |
|---|
| Jun | 60.0 |
|---|
Select columns without NaNs
1
| df.loc[:, df.notnull().all()]
|
| eggs | spam |
|---|
| month | | |
|---|
| Jan | 47 | 17 |
|---|
| Feb | 110 | 31 |
|---|
| Mar | 221 | 72 |
|---|
| Apr | 77 | 20 |
|---|
| May | 132 | 52 |
|---|
| Jun | 205 | 55 |
|---|
Drop rows with any NaNs
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
| Jun | 205 | 60.0 | 55 |
|---|
Filtering a column based on another
1
2
3
4
5
| month
Mar 221
Apr 77
Jun 205
Name: eggs, dtype: int64
|
Modifying a column based on another
1
2
| df.loc[df.salt > 55, 'eggs'] += 5
df
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 226 | 89.0 | 72 |
|---|
| Apr | 82 | 87.0 | 20 |
|---|
| May | 132 | NaN | 52 |
|---|
| Jun | 210 | 60.0 | 55 |
|---|
Exercises
Thresholding data
In this exercise, we have provided the Pennsylvania election results and included a column called ‘turnout’ that contains the percentage of voter turnout per county. Your job is to prepare a boolean array to select all of the rows and columns where voter turnout exceeded 70%.
As before, the DataFrame is available to you as election with the index set to ‘county’.
Instructions
- Create a boolean array of the condition where the ‘turnout’ column is greater than 70 and assign it to high_turnout.
- Filter the election DataFrame with the high_turnout array and assign it to high_turnout_df.
- Print the filtered DataFrame. This has been done for you, so hit ‘Submit Answer’ to see it!
1
| election = pd.read_csv(election_penn, index_col='county')
|
1
2
3
4
5
6
7
8
| # Create the boolean array: high_turnout
high_turnout = election.turnout > 70
# Filter the election DataFrame with the high_turnout array: high_turnout_df
high_turnout_df = election[high_turnout]
# Print the high_turnout_results DataFrame
high_turnout_df
|
| state | total | Obama | Romney | winner | voters | turnout | margin |
|---|
| county | | | | | | | | |
|---|
| Bucks | PA | 319407 | 49.966970 | 48.801686 | Obama | 435606 | 73.324748 | 1.165284 |
|---|
| Butler | PA | 88924 | 31.920516 | 66.816607 | Romney | 122762 | 72.436096 | 34.896091 |
|---|
| Chester | PA | 248295 | 49.228539 | 49.650617 | Romney | 337822 | 73.498766 | 0.422079 |
|---|
| Forest | PA | 2308 | 38.734835 | 59.835355 | Romney | 3232 | 71.410891 | 21.100520 |
|---|
| Franklin | PA | 62802 | 30.110506 | 68.583803 | Romney | 87406 | 71.850903 | 38.473297 |
|---|
| Montgomery | PA | 401787 | 56.637223 | 42.286834 | Obama | 551105 | 72.905708 | 14.350390 |
|---|
| Westmoreland | PA | 168709 | 37.567646 | 61.306154 | Romney | 238006 | 70.884347 | 23.738508 |
|---|
Filtering columns using other columns
The election results DataFrame has a column labeled ‘margin’ which expresses the number of extra votes the winner received over the losing candidate. This number is given as a percentage of the total votes cast. It is reasonable to assume that in counties where this margin was less than 1%, the results would be too-close-to-call.
Your job is to use boolean selection to filter the rows where the margin was less than 1. You’ll then convert these rows of the ‘winner’ column to np.nan to indicate that these results are too close to declare a winner.
The DataFrame has been pre-loaded for you as election.
Instructions
- Import numpy as np.
- Create a boolean array for the condition where the ‘margin’ column is less than 1 and assign it to too_close.
- Convert the entries in the ‘winner’ column where the result was too close to call to np.nan.
- Print the output of election.info(). This has been done for you, so hit ‘Submit Answer’ to see the results.
1
2
3
4
5
6
7
8
| # Create the boolean array: too_close
too_close = election.margin < 1
# Assign np.nan to the 'winner' column where the results were too close to call
election.loc[too_close, 'winner'] = NaN
# Print the output of election.info()
election.info()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <class 'pandas.core.frame.DataFrame'>
Index: 67 entries, Adams to York
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 state 67 non-null object
1 total 67 non-null int64
2 Obama 67 non-null float64
3 Romney 67 non-null float64
4 winner 64 non-null object
5 voters 67 non-null int64
6 turnout 67 non-null float64
7 margin 67 non-null float64
dtypes: float64(4), int64(2), object(2)
memory usage: 4.7+ KB
|
Filtering using NaNs
In certain scenarios, it may be necessary to remove rows and columns with missing data from a DataFrame. The .dropna() method is used to perform this action. You’ll now practice using this method on a dataset obtained from Vanderbilt University, which consists of data from passengers on the Titanic.
The DataFrame has been pre-loaded for you as titanic. Explore it in the IPython Shell and you will note that there are many NaNs. You will focus specifically on the ‘age’ and ‘cabin’ columns in this exercise. Your job is to use .dropna() to remove rows where any of these two columns contains missing data and rows where all of these two columns contain missing data.
You’ll also use the .shape attribute, which returns the number of rows and columns in a tuple from a DataFrame, or the number of rows from a Series, to see the effect of dropping missing values from a DataFrame.
Finally, you’ll use the thresh= keyword argument to drop columns from the full dataset that have less than 1000 non-missing values.
Instructions
- Select the ‘age’ and ‘cabin’ columns of titanic and create a new DataFrame df.
- Print the shape of df. This has been done for you.
- Drop rows in df with how=’any’ and print the shape.
- Drop rows in df with how=’all’ and print the shape.
- Drop columns from the titanic DataFrame that have less than 1000 non-missing values by specifying the thresh and axis keyword arguments. Print the output of .info() from this.
1
| titanic = pd.read_csv(titanic_data)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # Select the 'age' and 'cabin' columns: df
df = titanic[['age', 'cabin']]
# Print the shape of df
print(df.shape)
# Drop rows in df with how='any' and print the shape
print('\n', df.dropna(how='any').shape)
# Drop rows in df with how='all' and print the shape
print('\n', df.dropna(how='all').shape)
# Drop columns in titanic with less than 1000 non-missing values
print('\n', titanic.dropna(thresh=1000, axis='columns').info())
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| (1309, 2)
(272, 2)
(1069, 2)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 1309 non-null int64
1 survived 1309 non-null int64
2 name 1309 non-null object
3 sex 1309 non-null object
4 age 1046 non-null float64
5 sibsp 1309 non-null int64
6 parch 1309 non-null int64
7 ticket 1309 non-null object
8 fare 1308 non-null float64
9 embarked 1307 non-null object
dtypes: float64(2), int64(4), object(4)
memory usage: 102.4+ KB
None
|
Data
1
2
| df = pd.read_csv(sales_data, index_col='month')
df
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
| May | 132 | NaN | 52 |
|---|
| Jun | 205 | 60.0 | 55 |
|---|
DataFrame vectorized methods
1
| df.floordiv(12) # Convert to dozens unit
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 3 | 1.0 | 1 |
|---|
| Feb | 9 | 4.0 | 2 |
|---|
| Mar | 18 | 7.0 | 6 |
|---|
| Apr | 6 | 7.0 | 1 |
|---|
| May | 11 | NaN | 4 |
|---|
| Jun | 17 | 5.0 | 4 |
|---|
NumPy vectorized functions
1
| np.floor_divide(df, 12) # Convert to dozens unit
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 3 | 1.0 | 1 |
|---|
| Feb | 9 | 4.0 | 2 |
|---|
| Mar | 18 | 7.0 | 6 |
|---|
| Apr | 6 | 7.0 | 1 |
|---|
| May | 11 | NaN | 4 |
|---|
| Jun | 17 | 5.0 | 4 |
|---|
Plain Python functions (1)
1
2
| def dozens(n):
return n//12
|
1
| df.apply(dozens) # Convert to dozens unit
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 3 | 1.0 | 1 |
|---|
| Feb | 9 | 4.0 | 2 |
|---|
| Mar | 18 | 7.0 | 6 |
|---|
| Apr | 6 | 7.0 | 1 |
|---|
| May | 11 | NaN | 4 |
|---|
| Jun | 17 | 5.0 | 4 |
|---|
Plain Python functions (2)
1
| df.apply(lambda n: n//12)
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 3 | 1.0 | 1 |
|---|
| Feb | 9 | 4.0 | 2 |
|---|
| Mar | 18 | 7.0 | 6 |
|---|
| Apr | 6 | 7.0 | 1 |
|---|
| May | 11 | NaN | 4 |
|---|
| Jun | 17 | 5.0 | 4 |
|---|
1
2
| df['dozens_of_eggs'] = df.eggs.floordiv(12)
df
|
| eggs | salt | spam | dozens_of_eggs |
|---|
| month | | | | |
|---|
| Jan | 47 | 12.0 | 17 | 3 |
|---|
| Feb | 110 | 50.0 | 31 | 9 |
|---|
| Mar | 221 | 89.0 | 72 | 18 |
|---|
| Apr | 77 | 87.0 | 20 | 6 |
|---|
| May | 132 | NaN | 52 | 11 |
|---|
| Jun | 205 | 60.0 | 55 | 17 |
|---|
The DataFrame index
1
| Index(['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun'], dtype='object', name='month')
|
Working with string values (1)
1
2
| df.index = df.index.str.upper()
df
|
| eggs | salt | spam | dozens_of_eggs |
|---|
| month | | | | |
|---|
| JAN | 47 | 12.0 | 17 | 3 |
|---|
| FEB | 110 | 50.0 | 31 | 9 |
|---|
| MAR | 221 | 89.0 | 72 | 18 |
|---|
| APR | 77 | 87.0 | 20 | 6 |
|---|
| MAY | 132 | NaN | 52 | 11 |
|---|
| JUN | 205 | 60.0 | 55 | 17 |
|---|
Working with string values (2)
1
2
| df.index = df.index.map(str.lower)
df
|
| eggs | salt | spam | dozens_of_eggs |
|---|
| month | | | | |
|---|
| jan | 47 | 12.0 | 17 | 3 |
|---|
| feb | 110 | 50.0 | 31 | 9 |
|---|
| mar | 221 | 89.0 | 72 | 18 |
|---|
| apr | 77 | 87.0 | 20 | 6 |
|---|
| may | 132 | NaN | 52 | 11 |
|---|
| jun | 205 | 60.0 | 55 | 17 |
|---|
Defining columns using other columns
1
2
| df['salty_eggs'] = df.salt + df.dozens_of_eggs
df
|
| eggs | salt | spam | dozens_of_eggs | salty_eggs |
|---|
| month | | | | | |
|---|
| jan | 47 | 12.0 | 17 | 3 | 15.0 |
|---|
| feb | 110 | 50.0 | 31 | 9 | 59.0 |
|---|
| mar | 221 | 89.0 | 72 | 18 | 107.0 |
|---|
| apr | 77 | 87.0 | 20 | 6 | 93.0 |
|---|
| may | 132 | NaN | 52 | 11 | NaN |
|---|
| jun | 205 | 60.0 | 55 | 17 | 77.0 |
|---|
Exercises
The .apply() method can be used on a pandas DataFrame to apply an arbitrary Python function to every element. In this exercise you’ll take daily weather data in Pittsburgh in 2013 obtained from Weather Underground.
A function to convert degree Fahrenheit to degree Celsius has been written for you. Your job is to use the .apply() method to perform this conversion on the ‘Mean TemperatureF’ and ‘Mean Dew PointF’ columns of the weather DataFrame.
Instructions
- Apply the to_celsius() function over the [‘Mean TemperatureF’,’Mean Dew PointF’] columns of the weather DataFrame.
- Reassign the columns of df_celsius to [‘Mean TemperatureC’,’Mean Dew PointC’].
- Hit ‘Submit Answer’ to see the new DataFrame with the converted units.
1
| weather = pd.read_csv(weather_data)
|
1
2
3
| # Write a function to convert degree Fahrenheit to degree Celsius: to_celsius
def to_celsius(F):
return 5/9*(F - 32)
|
1
2
3
| # Apply the function over 'Mean TemperatureF' and 'Mean Dew PointF': df_celsius
df_celsius = weather[['Mean TemperatureF', 'Mean Dew PointF']].apply(to_celsius)
df_celsius.head()
|
| Mean TemperatureF | Mean Dew PointF |
|---|
| 0 | -2.222222 | -2.777778 |
|---|
| 1 | -6.111111 | -11.111111 |
|---|
| 2 | -4.444444 | -9.444444 |
|---|
| 3 | -2.222222 | -7.222222 |
|---|
| 4 | -1.111111 | -6.666667 |
|---|
1
2
3
| # Reassign the columns df_celsius
df_celsius.columns = ['Mean TemperatureC', 'Mean Dew PointC']
df_celsius.head()
|
| Mean TemperatureC | Mean Dew PointC |
|---|
| 0 | -2.222222 | -2.777778 |
|---|
| 1 | -6.111111 | -11.111111 |
|---|
| 2 | -4.444444 | -9.444444 |
|---|
| 3 | -2.222222 | -7.222222 |
|---|
| 4 | -1.111111 | -6.666667 |
|---|
Using .map() with a dictionary
The .map() method is used to transform values according to a Python dictionary look-up. In this exercise you’ll practice this method while returning to working with the election DataFrame, which has been pre-loaded for you.
Your job is to use a dictionary to map the values ‘Obama’ and ‘Romney’ in the ‘winner’ column to the values ‘blue’ and ‘red’, and assign the output to the new column ‘color’.
Instructions
- Create a dictionary with the key:value pairs ‘Obama’:’blue’ and ‘Romney’:’red’.
- Use the .map() method on the ‘winner’ column using the red_vs_blue dictionary you created.
- Print the output of election.head(). This has been done for you, so hit ‘Submit Answer’ to see the new column!
1
2
| election = pd.read_csv(election_penn, index_col='county')
election.head()
|
| state | total | Obama | Romney | winner | voters | turnout | margin |
|---|
| county | | | | | | | | |
|---|
| Adams | PA | 41973 | 35.482334 | 63.112001 | Romney | 61156 | 68.632677 | 27.629667 |
|---|
| Allegheny | PA | 614671 | 56.640219 | 42.185820 | Obama | 924351 | 66.497575 | 14.454399 |
|---|
| Armstrong | PA | 28322 | 30.696985 | 67.901278 | Romney | 42147 | 67.198140 | 37.204293 |
|---|
| Beaver | PA | 80015 | 46.032619 | 52.637630 | Romney | 115157 | 69.483401 | 6.605012 |
|---|
| Bedford | PA | 21444 | 22.057452 | 76.986570 | Romney | 32189 | 66.619031 | 54.929118 |
|---|
1
2
3
4
5
6
7
8
| # Create the dictionary: red_vs_blue
red_vs_blue = {'Obama':'blue', 'Romney':'red'}
# Use the dictionary to map the 'winner' column to the new column: election['color']
election['color'] = election.winner.map(red_vs_blue)
# Print the output of election.head()
election.head()
|
| state | total | Obama | Romney | winner | voters | turnout | margin | color |
|---|
| county | | | | | | | | | |
|---|
| Adams | PA | 41973 | 35.482334 | 63.112001 | Romney | 61156 | 68.632677 | 27.629667 | red |
|---|
| Allegheny | PA | 614671 | 56.640219 | 42.185820 | Obama | 924351 | 66.497575 | 14.454399 | blue |
|---|
| Armstrong | PA | 28322 | 30.696985 | 67.901278 | Romney | 42147 | 67.198140 | 37.204293 | red |
|---|
| Beaver | PA | 80015 | 46.032619 | 52.637630 | Romney | 115157 | 69.483401 | 6.605012 | red |
|---|
| Bedford | PA | 21444 | 22.057452 | 76.986570 | Romney | 32189 | 66.619031 | 54.929118 | red |
|---|
Using vectorized functions
When performance is paramount, you should avoid using .apply() and .map() because those constructs perform Python for-loops over the data stored in a pandas Series or DataFrame. By using vectorized functions instead, you can loop over the data at the same speed as compiled code (C, Fortran, etc.)! NumPy, SciPy and pandas come with a variety of vectorized functions (called Universal Functions or UFuncs in NumPy).
You can even write your own vectorized functions, but for now we will focus on the ones distributed by NumPy and pandas.
In this exercise you’re going to import the zscore function from scipy.stats and use it to compute the deviation in voter turnout in Pennsylvania from the mean in fractions of the standard deviation. In statistics, the z-score is the number of standard deviations by which an observation is above the mean - so if it is negative, it means the observation is below the mean.
Instead of using .apply() as you did in the earlier exercises, the zscore UFunc will take a pandas Series as input and return a NumPy array. You will then assign the values of the NumPy array to a new column in the DataFrame. You will be working with the election DataFrame - it has been pre-loaded for you.
Instructions
- Import zscore from scipy.stats.
- Call zscore with election[‘turnout’] as input .
- Print the output of type(turnout_zscore). This has been done for you.
- Assign turnout_zscore to a new column in election as ‘turnout_zscore’.
- Print the output of election.head(). This has been done for you, so hit ‘Submit Answer’ to view the result.
1
2
3
4
5
6
7
8
9
10
11
| # Call zscore with election['turnout'] as input: turnout_zscore
turnout_zscore = zscore(election.turnout)
# Print the type of turnout_zscore
print('Type: \n', type(turnout_zscore), '\n')
# Assign turnout_zscore to a new column: election['turnout_zscore']
election['turnout_zscore'] = turnout_zscore
# Print the output of election.head()
election.head()
|
1
2
| Type:
<class 'pandas.core.series.Series'>
|
| state | total | Obama | Romney | winner | voters | turnout | margin | color | turnout_zscore |
|---|
| county | | | | | | | | | | |
|---|
| Adams | PA | 41973 | 35.482334 | 63.112001 | Romney | 61156 | 68.632677 | 27.629667 | red | 0.853734 |
|---|
| Allegheny | PA | 614671 | 56.640219 | 42.185820 | Obama | 924351 | 66.497575 | 14.454399 | blue | 0.439846 |
|---|
| Armstrong | PA | 28322 | 30.696985 | 67.901278 | Romney | 42147 | 67.198140 | 37.204293 | red | 0.575650 |
|---|
| Beaver | PA | 80015 | 46.032619 | 52.637630 | Romney | 115157 | 69.483401 | 6.605012 | red | 1.018647 |
|---|
| Bedford | PA | 21444 | 22.057452 | 76.986570 | Romney | 32189 | 66.619031 | 54.929118 | red | 0.463391 |
|---|
Advanced Indexing
Having learned the fundamentals of working with DataFrames, you will now move on to more advanced indexing techniques. You will learn about MultiIndexes, or hierarchical indexes, and learn how to interact with and extract data from them.
Index objects and labeled data
pandas Data Structures
- Key building blocks
- Indexes: Sequence of lables
- Series: 1D array with index
- DataFrames: 2D array with Series as columns
- Indexes
- Immutable (Like dictionary keys)
- Homogenous in data type (Like NumPy arrays)
Creating a Series
1
2
3
| prices = [10.70, 10.86, 10.74, 10.71, 10.79]
shares = pd.Series(prices)
shares
|
1
2
3
4
5
6
| 0 10.70
1 10.86
2 10.74
3 10.71
4 10.79
dtype: float64
|
Creating an index
1
2
3
| days = ['Mon', 'Tue', 'Wed', 'Thur', 'Fri']
shares = pd.Series(prices, index=days)
shares
|
1
2
3
4
5
6
| Mon 10.70
Tue 10.86
Wed 10.74
Thur 10.71
Fri 10.79
dtype: float64
|
Examining an index
1
2
3
4
5
| print(shares.index)
print(shares.index[2])
print(shares.index[:2])
print(shares.index[-2:])
print(shares.index.name)
|
1
2
3
4
5
| Index(['Mon', 'Tue', 'Wed', 'Thur', 'Fri'], dtype='object')
Wed
Index(['Mon', 'Tue'], dtype='object')
Index(['Thur', 'Fri'], dtype='object')
None
|
Modifying index name
1
2
| shares.index.name = 'weekday'
shares
|
1
2
3
4
5
6
7
| weekday
Mon 10.70
Tue 10.86
Wed 10.74
Thur 10.71
Fri 10.79
dtype: float64
|
Modifying index entries
1
2
3
4
| try:
shares.index[2] = 'Wednesday'
except TypeError:
print('TypeError: Index does not support mutable operations')
|
1
| TypeError: Index does not support mutable operations
|
1
2
3
4
| try:
shares.index[:4]= ['Monday', 'Tuesday', 'Wednesday', 'Thursday']
except TypeError:
print('TypeError: Index does not support mutable operations')
|
1
| TypeError: Index does not support mutable operations
|
Modifying all index entries
1
2
| shares.index = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
shares
|
1
2
3
4
5
6
| Monday 10.70
Tuesday 10.86
Wednesday 10.74
Thursday 10.71
Friday 10.79
dtype: float64
|
Unemployment data - Massachusetts
1
2
3
4
5
6
7
8
9
10
11
| # Read the csv file
unemployment = pd.read_csv('data/manipulating-dataframes-with-pandas/LURReport.csv')
# Combine 'Year' and 'Month' columns and convert to datetime
unemployment['Year_Month'] = pd.to_datetime(unemployment['Year'].astype(str) + '-' + unemployment['Month'].astype(str), format='%Y-%B')
# Drop the 'Year' and 'Month' columns
unemployment.drop(['Year', 'Month'], axis=1, inplace=True)
# Show the first 5 rows
unemployment.head()
|
| Area | Labor Force | Employed | Unemployed | Area Rate | Massachusetts Rate | Year_Month |
|---|
| 0 | Barnstable County | 112,449 | 107,669 | 4,780 | 4.3 | 2.7 | 2018-12-01 |
|---|
| 1 | Barnstable County | 112,150 | 108,171 | 3,979 | 3.5 | 2.6 | 2018-11-01 |
|---|
| 2 | Barnstable County | 115,665 | 112,127 | 3,538 | 3.1 | 2.9 | 2018-10-01 |
|---|
| 3 | Barnstable County | 119,420 | 115,757 | 3,663 | 3.1 | 3.2 | 2018-09-01 |
|---|
| 4 | Barnstable County | 129,627 | 125,636 | 3,991 | 3.1 | 3.5 | 2018-08-01 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <class 'pandas.core.frame.DataFrame'>
RangeIndex: 182 entries, 0 to 181
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Area 182 non-null object
1 Labor Force 182 non-null object
2 Employed 182 non-null object
3 Unemployed 182 non-null object
4 Area Rate 182 non-null float64
5 Massachusetts Rate 182 non-null float64
6 Year_Month 182 non-null datetime64[ns]
dtypes: datetime64[ns](1), float64(2), object(4)
memory usage: 10.1+ KB
|
Assigning the index
1
2
| unemployment.index = unemployment.Area
unemployment.head()
|
| Area | Labor Force | Employed | Unemployed | Area Rate | Massachusetts Rate | Year_Month |
|---|
| Area | | | | | | | |
|---|
| Barnstable County | Barnstable County | 112,449 | 107,669 | 4,780 | 4.3 | 2.7 | 2018-12-01 |
|---|
| Barnstable County | Barnstable County | 112,150 | 108,171 | 3,979 | 3.5 | 2.6 | 2018-11-01 |
|---|
| Barnstable County | Barnstable County | 115,665 | 112,127 | 3,538 | 3.1 | 2.9 | 2018-10-01 |
|---|
| Barnstable County | Barnstable County | 119,420 | 115,757 | 3,663 | 3.1 | 3.2 | 2018-09-01 |
|---|
| Barnstable County | Barnstable County | 129,627 | 125,636 | 3,991 | 3.1 | 3.5 | 2018-08-01 |
|---|
Removing extr column
1
2
| del unemployment['Area']
unemployment.head()
|
| Labor Force | Employed | Unemployed | Area Rate | Massachusetts Rate | Year_Month |
|---|
| Area | | | | | | |
|---|
| Barnstable County | 112,449 | 107,669 | 4,780 | 4.3 | 2.7 | 2018-12-01 |
|---|
| Barnstable County | 112,150 | 108,171 | 3,979 | 3.5 | 2.6 | 2018-11-01 |
|---|
| Barnstable County | 115,665 | 112,127 | 3,538 | 3.1 | 2.9 | 2018-10-01 |
|---|
| Barnstable County | 119,420 | 115,757 | 3,663 | 3.1 | 3.2 | 2018-09-01 |
|---|
| Barnstable County | 129,627 | 125,636 | 3,991 | 3.1 | 3.5 | 2018-08-01 |
|---|
Examining index & columns
1
2
3
4
| print('Index: \n', unemployment.index)
print('\nIndex Name:\n', unemployment.index.name)
print('\nIndex Type:\n', type(unemployment.index))
print('\nDataFrame Columns\n', unemployment.columns)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| Index:
Index(['Barnstable County', 'Barnstable County', 'Barnstable County',
'Barnstable County', 'Barnstable County', 'Barnstable County',
'Barnstable County', 'Barnstable County', 'Barnstable County',
'Barnstable County',
...
'Worcester County', 'Worcester County', 'Worcester County',
'Worcester County', 'Worcester County', 'Worcester County',
'Worcester County', 'Worcester County', 'Worcester County',
'Worcester County'],
dtype='object', name='Area', length=182)
Index Name:
Area
Index Type:
<class 'pandas.core.indexes.base.Index'>
DataFrame Columns
Index(['Labor Force', 'Employed', 'Unemployed', 'Area Rate ',
'Massachusetts Rate ', 'Year_Month'],
dtype='object')
|
read_csv() with index_col()
1
2
3
4
5
6
7
8
9
10
11
| # Read the csv file
unemployment = pd.read_csv('data/manipulating-dataframes-with-pandas/LURReport.csv', index_col='Area')
# Combine 'Year' and 'Month' columns and convert to datetime
unemployment['Year_Month'] = pd.to_datetime(unemployment['Year'].astype(str) + '-' + unemployment['Month'].astype(str), format='%Y-%B')
# Drop the 'Year' and 'Month' columns
unemployment.drop(['Year', 'Month'], axis=1, inplace=True)
# Show the first 5 rows
unemployment.head()
|
| Labor Force | Employed | Unemployed | Area Rate | Massachusetts Rate | Year_Month |
|---|
| Area | | | | | | |
|---|
| Barnstable County | 112,449 | 107,669 | 4,780 | 4.3 | 2.7 | 2018-12-01 |
|---|
| Barnstable County | 112,150 | 108,171 | 3,979 | 3.5 | 2.6 | 2018-11-01 |
|---|
| Barnstable County | 115,665 | 112,127 | 3,538 | 3.1 | 2.9 | 2018-10-01 |
|---|
| Barnstable County | 119,420 | 115,757 | 3,663 | 3.1 | 3.2 | 2018-09-01 |
|---|
| Barnstable County | 129,627 | 125,636 | 3,991 | 3.1 | 3.5 | 2018-08-01 |
|---|
Exercises
Data
1
2
| df = pd.read_csv(sales_data, index_col='month')
df
|
| eggs | salt | spam |
|---|
| month | | | |
|---|
| Jan | 47 | 12.0 | 17 |
|---|
| Feb | 110 | 50.0 | 31 |
|---|
| Mar | 221 | 89.0 | 72 |
|---|
| Apr | 77 | 87.0 | 20 |
|---|
| May | 132 | NaN | 52 |
|---|
| Jun | 205 | 60.0 | 55 |
|---|
Index values and names
Which one of the following index operations does not raise an error?
The sales DataFrame which you have seen in the videos of the previous chapter has been pre-loaded for you and is available for exploration in the IPython Shell.
Instructions
Possible Answers
- sales.index[0] = ‘JAN’.
- sales.index[0] = sales.index[0].upper().
- sales.index = range(len(sales)).
Changing index of a DataFrame
As you saw in the previous exercise, indexes are immutable objects. This means that if you want to change or modify the index in a DataFrame, then you need to change the whole index. You will do this now, using a list comprehension to create the new index.
A list comprehension is a succinct way to generate a list in one line. For example, the following list comprehension generates a list that contains the cubes of all numbers from 0 to 9:
1
| cubes = [i**3 for i in range(10)]
|
This is equivalent to the following code:
1
2
3
| cubes = []
for i in range(10):
cubes.append(i**3)
|
Before getting started, print the sales DataFrame in the IPython Shell and verify that the index is given by month abbreviations containing lowercase characters.
Instructions
- Create a list new_idx with the same elements as in sales.index, but with all characters capitalized.
- Assign new_idx to sales.index.
- Print the sales dataframe. This has been done for you, so hit ‘Submit Answer’ and to see how the index changed.
1
2
3
4
5
6
7
8
| # Create the list of new indexes: new_idx
new_idx = [x.upper() for x in df.index]
# Assign new_idx to sales.index
df.index = new_idx
# Print the sales DataFrame
print(df)
|
1
2
3
4
5
6
7
| eggs salt spam
JAN 47 12.0 17
FEB 110 50.0 31
MAR 221 89.0 72
APR 77 87.0 20
MAY 132 NaN 52
JUN 205 60.0 55
|
Changing index name labels
Notice that in the previous exercise, the index was not labeled with a name. In this exercise, you will set its name to ‘MONTHS’.
Similarly, if all the columns are related in some way, you can provide a label for the set of columns.
To get started, print the sales DataFrame in the IPython Shell and verify that the index has no name, only its data (the month names).
Instructions
- Assign the string ‘MONTHS’ to sales.index.name to create a name for the index.
- Print the sales dataframe to see the index name you just created.
- Now assign the string ‘PRODUCTS’ to sales.columns.name to give a name to the set of columns.
- Print the sales dataframe again to see the columns name you just created.
1
2
3
4
5
6
7
8
9
10
11
| # Assign the string 'MONTHS' to sales.index.name
df.index.name = 'MONTHS'
# Print the sales DataFrame
print(df)
# Assign the string 'PRODUCTS' to sales.columns.name
df.columns.name = 'PRODUCTS'
# Print the sales dataframe again
print('\n', df)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| eggs salt spam
MONTHS
JAN 47 12.0 17
FEB 110 50.0 31
MAR 221 89.0 72
APR 77 87.0 20
MAY 132 NaN 52
JUN 205 60.0 55
PRODUCTS eggs salt spam
MONTHS
JAN 47 12.0 17
FEB 110 50.0 31
MAR 221 89.0 72
APR 77 87.0 20
MAY 132 NaN 52
JUN 205 60.0 55
|
Building an index, then a DataFrame
You can also build the DataFrame and index independently, and then put them together. If you take this route, be careful, as any mistakes in generating the DataFrame or the index can cause the data and the index to be aligned incorrectly.
In this exercise, the sales DataFrame has been provided for you without the month index. Your job is to build this index separately and then assign it to the sales DataFrame. Before getting started, print the sales DataFrame in the IPython Shell and note that it’s missing the month information.
Instructions
- Generate a list months with the data [‘Jan’, ‘Feb’, ‘Mar’, ‘Apr’, ‘May’, ‘Jun’]. This has been done for you.
- Assign months to sales.index.
- Print the modified sales dataframe and verify that you now have month information in the index.
1
2
| df = pd.read_csv(sales_data, usecols=['eggs', 'salt', 'spam'])
df
|
| eggs | salt | spam |
|---|
| 0 | 47 | 12.0 | 17 |
|---|
| 1 | 110 | 50.0 | 31 |
|---|
| 2 | 221 | 89.0 | 72 |
|---|
| 3 | 77 | 87.0 | 20 |
|---|
| 4 | 132 | NaN | 52 |
|---|
| 5 | 205 | 60.0 | 55 |
|---|
1
2
3
4
5
6
7
8
| # Generate the list of months: months
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun']
# Assign months to sales.index
df.index = months
# Print the modified sales DataFrame
print(df)
|
1
2
3
4
5
6
7
| eggs salt spam
Jan 47 12.0 17
Feb 110 50.0 31
Mar 221 89.0 72
Apr 77 87.0 20
May 132 NaN 52
Jun 205 60.0 55
|
Hierarchical indexing
Stock Data
1
2
3
4
5
6
7
8
9
10
11
| stocks = pd.DataFrame([['2016-10-03', 31.50, 14070500, 'CSCO'],
['2016-10-03', 112.52, 21701800, 'AAPL'],
['2016-10-03', 57.42, 19189500, 'MSFT'],
['2016-10-04', 113.00, 29736800, 'AAPL'],
['2016-10-04', 57.24, 20085900, 'MSFT'],
['2016-10-04', 31.35, 18460400, 'CSCO'],
['2016-10-05', 57.64, 16726400, 'MSFT'],
['2016-10-05', 31.59, 11808600, 'CSCO'],
['2016-10-05', 113.05, 21453100, 'AAPL']],
columns=['Date', 'Close', 'Volume', 'Symbol'])
stocks
|
| Date | Close | Volume | Symbol |
|---|
| 0 | 2016-10-03 | 31.50 | 14070500 | CSCO |
|---|
| 1 | 2016-10-03 | 112.52 | 21701800 | AAPL |
|---|
| 2 | 2016-10-03 | 57.42 | 19189500 | MSFT |
|---|
| 3 | 2016-10-04 | 113.00 | 29736800 | AAPL |
|---|
| 4 | 2016-10-04 | 57.24 | 20085900 | MSFT |
|---|
| 5 | 2016-10-04 | 31.35 | 18460400 | CSCO |
|---|
| 6 | 2016-10-05 | 57.64 | 16726400 | MSFT |
|---|
| 7 | 2016-10-05 | 31.59 | 11808600 | CSCO |
|---|
| 8 | 2016-10-05 | 113.05 | 21453100 | AAPL |
|---|
Setting index
1
2
| stocks = stocks.set_index(['Symbol', 'Date'])
stocks
|
| | Close | Volume |
|---|
| Symbol | Date | | |
|---|
| CSCO | 2016-10-03 | 31.50 | 14070500 |
|---|
| AAPL | 2016-10-03 | 112.52 | 21701800 |
|---|
| MSFT | 2016-10-03 | 57.42 | 19189500 |
|---|
| AAPL | 2016-10-04 | 113.00 | 29736800 |
|---|
| MSFT | 2016-10-04 | 57.24 | 20085900 |
|---|
| CSCO | 2016-10-04 | 31.35 | 18460400 |
|---|
| MSFT | 2016-10-05 | 57.64 | 16726400 |
|---|
| CSCO | 2016-10-05 | 31.59 | 11808600 |
|---|
| AAPL | 2016-10-05 | 113.05 | 21453100 |
|---|
MultiIndex on DataFrame
1
2
3
4
5
6
7
8
9
10
| MultiIndex([('CSCO', '2016-10-03'),
('AAPL', '2016-10-03'),
('MSFT', '2016-10-03'),
('AAPL', '2016-10-04'),
('MSFT', '2016-10-04'),
('CSCO', '2016-10-04'),
('MSFT', '2016-10-05'),
('CSCO', '2016-10-05'),
('AAPL', '2016-10-05')],
names=['Symbol', 'Date'])
|
1
2
| print(stocks.index.name)
print(stocks.index.names)
|
1
2
| None
['Symbol', 'Date']
|
Sorting index
1
2
| stocks = stocks.sort_index()
stocks
|
| | Close | Volume |
|---|
| Symbol | Date | | |
|---|
| AAPL | 2016-10-03 | 112.52 | 21701800 |
|---|
| 2016-10-04 | 113.00 | 29736800 |
|---|
| 2016-10-05 | 113.05 | 21453100 |
|---|
| CSCO | 2016-10-03 | 31.50 | 14070500 |
|---|
| 2016-10-04 | 31.35 | 18460400 |
|---|
| 2016-10-05 | 31.59 | 11808600 |
|---|
| MSFT | 2016-10-03 | 57.42 | 19189500 |
|---|
| 2016-10-04 | 57.24 | 20085900 |
|---|
| 2016-10-05 | 57.64 | 16726400 |
|---|
Indexing (individual row)
1
| stocks.loc[('CSCO', '2016-10-04')]
|
1
2
3
| Close 31.35
Volume 18460400.00
Name: (CSCO, 2016-10-04), dtype: float64
|
1
| stocks.loc[('CSCO', '2016-10-04'), 'Volume']
|
Slicing (outermost index)
| Close | Volume |
|---|
| Date | | |
|---|
| 2016-10-03 | 112.52 | 21701800 |
|---|
| 2016-10-04 | 113.00 | 29736800 |
|---|
| 2016-10-05 | 113.05 | 21453100 |
|---|
Slicing (outermost index)
1
| stocks.loc['CSCO':'MSFT']
|
| | Close | Volume |
|---|
| Symbol | Date | | |
|---|
| CSCO | 2016-10-03 | 31.50 | 14070500 |
|---|
| 2016-10-04 | 31.35 | 18460400 |
|---|
| 2016-10-05 | 31.59 | 11808600 |
|---|
| MSFT | 2016-10-03 | 57.42 | 19189500 |
|---|
| 2016-10-04 | 57.24 | 20085900 |
|---|
| 2016-10-05 | 57.64 | 16726400 |
|---|
Fancy indexing (outermost index)
1
| stocks.loc[(['AAPL', 'MSFT'], '2016-10-05'), :]
|
| | Close | Volume |
|---|
| Symbol | Date | | |
|---|
| AAPL | 2016-10-05 | 113.05 | 21453100 |
|---|
| MSFT | 2016-10-05 | 57.64 | 16726400 |
|---|
1
| stocks.loc[(['AAPL', 'MSFT'], '2016-10-05'), 'Close']
|
1
2
3
4
| Symbol Date
AAPL 2016-10-05 113.05
MSFT 2016-10-05 57.64
Name: Close, dtype: float64
|
Fancy indexing (innermost index)
1
| stocks.loc[('CSCO', ['2016-10-05', '2016-10-03']), :]
|
| | Close | Volume |
|---|
| Symbol | Date | | |
|---|
| CSCO | 2016-10-05 | 31.59 | 11808600 |
|---|
| 2016-10-03 | 31.50 | 14070500 |
|---|
Slicing (both indexes)
1
| stocks.loc[(slice(None), slice('2016-10-03', '2016-10-04')),:]
|
| | Close | Volume |
|---|
| Symbol | Date | | |
|---|
| AAPL | 2016-10-03 | 112.52 | 21701800 |
|---|
| 2016-10-04 | 113.00 | 29736800 |
|---|
| CSCO | 2016-10-03 | 31.50 | 14070500 |
|---|
| 2016-10-04 | 31.35 | 18460400 |
|---|
| MSFT | 2016-10-03 | 57.42 | 19189500 |
|---|
| 2016-10-04 | 57.24 | 20085900 |
|---|
Exercises
Sales Data
1
2
| sales = pd.read_csv(sales2_data, index_col=['state', 'month'])
sales
|
| | eggs | salt | spam |
|---|
| state | month | | | |
|---|
| CA | 1 | 47 | 12.0 | 17 |
|---|
| 2 | 110 | 50.0 | 31 |
|---|
| NY | 1 | 221 | 89.0 | 72 |
|---|
| 2 | 77 | 87.0 | 20 |
|---|
| TX | 1 | 132 | NaN | 52 |
|---|
| 2 | 205 | 60.0 | 55 |
|---|
In the video, Dhavide explained the concept of a hierarchical index, or a MultiIndex. You will now practice working with these types of indexes.
The sales DataFrame you have been working with has been extended to now include State information as well. In the IPython Shell, print the new sales DataFrame to inspect the data. Take note of the MultiIndex!
Extracting elements from the outermost level of a MultiIndex is just like in the case of a single-level Index. You can use the .loc[] accessor as Dhavide demonstrated in the video.
Instructions
- Print sales.loc[[‘CA’, ‘TX’]]. Note how New York is excluded.
- Print sales[‘CA’:’TX’]. Note how New York is included.
1
2
3
4
5
| # Print sales.loc[['CA', 'TX']]
print(sales.loc[['CA', 'TX']])
# Print sales['CA':'TX']
print('\n', sales['CA':'TX'])
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| eggs salt spam
state month
CA 1 47 12.0 17
2 110 50.0 31
TX 1 132 NaN 52
2 205 60.0 55
eggs salt spam
state month
CA 1 47 12.0 17
2 110 50.0 31
NY 1 221 89.0 72
2 77 87.0 20
TX 1 132 NaN 52
2 205 60.0 55
|
Notice how New York is excluded by the first operation, and included in the second one.
Setting & sorting a MultiIndex
In the previous exercise, the MultiIndex was created and sorted for you. Now, you’re going to do this yourself! With a MultiIndex, you should always ensure the index is sorted. You can skip this only if you know the data is already sorted on the index fields.
To get started, print the pre-loaded sales DataFrame in the IPython Shell to verify that there is no MultiIndex.
Instructions
- Create a MultiIndex by setting the index to be the columns [‘state’, ‘month’].
- Sort the MultiIndex using the .sort_index() method.
- Print the sales DataFrame. This has been done for you, so hit ‘Submit Answer’ to verify that indeed you have an index with the fields state and month!
1
2
3
4
5
6
7
8
9
10
| sales = pd.read_csv(sales2_data)
# Set the index to be the columns ['state', 'month']: sales
sales = sales.set_index(['state', 'month'])
# Sort the MultiIndex: sales
sales = sales.sort_index()
# Print the sales DataFrame
sales
|
| | eggs | salt | spam |
|---|
| state | month | | | |
|---|
| CA | 1 | 47 | 12.0 | 17 |
|---|
| 2 | 110 | 50.0 | 31 |
|---|
| NY | 1 | 221 | 89.0 | 72 |
|---|
| 2 | 77 | 87.0 | 20 |
|---|
| TX | 1 | 132 | NaN | 52 |
|---|
| 2 | 205 | 60.0 | 55 |
|---|
Using .loc[] with nonunique indexes
As Dhavide mentioned in the video, it is always preferable to have a meaningful index that uniquely identifies each row. Even though pandas does not require unique index values in DataFrames, it works better if the index values are indeed unique. To see an example of this, you will index your sales data by ‘state’ in this exercise.
As always, begin by printing the sales DataFrame in the IPython Shell and inspecting it.
Instructions
- Set the index of sales to be the column ‘state’.
- Print the sales DataFrame to verify that indeed you have an index with state values.
- Access the data from ‘NY’ and print it to verify that you obtain two rows.
1
2
3
4
5
6
7
8
9
10
| sales = pd.read_csv(sales2_data)
# Set the index to the column 'state': sales
sales = sales.set_index('state')
# Print the sales DataFrame
print(sales)
# Access the data from 'NY'
print('\n', sales.loc['NY'])
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| month eggs salt spam
state
CA 1 47 12.0 17
CA 2 110 50.0 31
NY 1 221 89.0 72
NY 2 77 87.0 20
TX 1 132 NaN 52
TX 2 205 60.0 55
month eggs salt spam
state
NY 1 221 89.0 72
NY 2 77 87.0 20
|
Indexing multiple levels of a MultiIndex
Looking up indexed data is fast and efficient. And you have already seen that lookups based on the outermost level of a MultiIndex work just like lookups on DataFrames that have a single-level Index.
Looking up data based on inner levels of a MultiIndex can be a bit trickier. In this exercise, you will use your sales DataFrame to do some increasingly complex lookups.
The trickiest of all these lookups are when you want to access some inner levels of the index. In this case, you need to use slice(None) in the slicing parameter for the outermost dimension(s) instead of the usual :, or use pd.IndexSlice. You can refer to the pandas documentation for more details. For example, in the video, Dhavide used the following code to extract rows from all Symbols for the dates Oct. 3rd through 4th inclusive:
1
| stocks.loc[(slice(None), slice('2016-10-03', '2016-10-04')), :]
|
Pay particular attention to the tuple:
1
| (slice(None), slice('2016-10-03', '2016-10-04')).
|
Instructions
- Look up data for the New York column (‘NY’) in month 1.
- Look up data for the California and Texas columns (‘CA’, ‘TX’) in month 2.
- Look up data for all states in month 2. Use (slice(None), 2) to extract all rows in month 2
1
2
| sales = pd.read_csv(sales2_data, index_col=['state', 'month'])
sales
|
| | eggs | salt | spam |
|---|
| state | month | | | |
|---|
| CA | 1 | 47 | 12.0 | 17 |
|---|
| 2 | 110 | 50.0 | 31 |
|---|
| NY | 1 | 221 | 89.0 | 72 |
|---|
| 2 | 77 | 87.0 | 20 |
|---|
| TX | 1 | 132 | NaN | 52 |
|---|
| 2 | 205 | 60.0 | 55 |
|---|
1
2
3
| # Look up data for NY in month 1: NY_month1
NY_month1 = sales.loc[('NY', 1), :]
NY_month1
|
1
2
3
4
| eggs 221.0
salt 89.0
spam 72.0
Name: (NY, 1), dtype: float64
|
1
2
3
| # Look up data for CA and TX in month 2: CA_TX_month2
CA_TX_month2 = sales.loc[(('CA', 'TX'), 2), :]
CA_TX_month2
|
| | eggs | salt | spam |
|---|
| state | month | | | |
|---|
| CA | 2 | 110 | 50.0 | 31 |
|---|
| TX | 2 | 205 | 60.0 | 55 |
|---|
1
2
3
| # Look up data for all states in month 2: all_month2
all_month2 = sales.loc[(slice(None), 2), :]
all_month2
|
| | eggs | salt | spam |
|---|
| state | month | | | |
|---|
| CA | 2 | 110 | 50.0 | 31 |
|---|
| NY | 2 | 77 | 87.0 | 20 |
|---|
| TX | 2 | 205 | 60.0 | 55 |
|---|
Rearranging and reshaping data
Here, you will learn how to reshape your DataFrames using techniques such as pivoting, melting, stacking, and unstacking. These are powerful techniques that allow you to tidy and rearrange your data into the format that allows you to most easily analyze it for insights.
Pivoting DataFrames
Clinical Trials Data
1
2
3
4
5
6
| trials = pd.DataFrame([[1, 'A', 'F', 5],
[2, 'A', 'M', 3],
[3, 'B', 'F', 8],
[4, 'B', 'M', 9]],
columns=['id', 'treatment', 'gender', 'response'])
trials
|
| id | treatment | gender | response |
|---|
| 0 | 1 | A | F | 5 |
|---|
| 1 | 2 | A | M | 3 |
|---|
| 2 | 3 | B | F | 8 |
|---|
| 3 | 4 | B | M | 9 |
|---|
Reshaping by pivoting
1
2
3
| trials.pivot(index='treatment',
columns='gender',
values='response')
|
Pivoting multiple columns
1
| trials.pivot(index='treatment', columns='gender')
|
| id | response |
|---|
| gender | F | M | F | M |
|---|
| treatment | | | | |
|---|
| A | 1 | 2 | 5 | 3 |
|---|
| B | 3 | 4 | 8 | 9 |
|---|
Exercises
Pivoting and the index
Prior to using .pivot(), you need to set the index of the DataFrame somehow. Is this statement True or False?
Answer the question
False
Pivoting a single variable
Suppose you started a blog for a band, and you would like to log how many visitors you have had, and how many signed-up for your newsletter. To help design the tours later, you track where the visitors are. A DataFrame called users consisting of this information has been pre-loaded for you.
Inspect users in the IPython Shell and make a note of which variable you want to use to index the rows (‘weekday’), which variable you want to use to index the columns (‘city’), and which variable will populate the values in the cells (‘visitors’). Try to visualize what the result should be.
For example, in the video, Dhavide used ‘treatment’ to index the rows, ‘gender’ to index the columns, and ‘response’ to populate the cells. Prior to pivoting, the DataFrame looked like this:
1
2
3
4
5
| id treatment gender response
0 1 A F 5
1 2 A M 3
2 3 B F 8
3 4 B M 9
|
After pivoting:
1
2
3
4
| gender F M
treatment
A 5 3
B 8 9
|
In this exercise, your job is to pivot users so that the focus is on ‘visitors’, with the columns indexed by ‘city’ and the rows indexed by ‘weekday’.
Instructions
- Pivot the users DataFrame with the rows indexed by ‘weekday’, the columns indexed by ‘city’, and the values populated with ‘visitors’.
- Print the pivoted DataFrame. This has been done for you, so hit ‘Submit Answer’ to view the result.
1
2
| users = pd.read_csv(users_data)
users
|
| weekday | city | visitors | signups |
|---|
| 0 | Sun | Austin | 139 | 7 |
|---|
| 1 | Sun | Dallas | 237 | 12 |
|---|
| 2 | Mon | Austin | 326 | 3 |
|---|
| 3 | Mon | Dallas | 456 | 5 |
|---|
1
2
3
4
5
| # Pivot the users DataFrame: visitors_pivot
visitors_pivot = users.pivot(index='weekday',
columns='city',
values='visitors')
visitors_pivot
|
| city | Austin | Dallas |
|---|
| weekday | | |
|---|
| Mon | 326 | 456 |
|---|
| Sun | 139 | 237 |
|---|
Notice how in the pivoted DataFrame, the index is labeled ‘weekday’, the columns are labeled ‘city’, and the values are populated by the number of visitors.
Pivoting all variables
If you do not select any particular variables, all of them will be pivoted. In this case - with the users DataFrame - both ‘visitors’ and ‘signups’ will be pivoted, creating hierarchical column labels.
You will explore this for yourself now in this exercise.
Instructions
- Pivot the users DataFrame with the ‘signups’ indexed by ‘weekday’ in the rows and ‘city’ in the columns.
- Print the new DataFrame. This has been done for you.
- Pivot the users DataFrame with both ‘signups’ and ‘visitors’ pivoted - that is, all the variables. This will happen automatically if you do not specify an argument for the values parameter of .pivot().
- Print the pivoted DataFrame. This has been done for you, so hit ‘Submit Answer’ to see the result.
1
2
3
| # Pivot users with signups indexed by weekday and city: signups_pivot
signups_pivot = users.pivot(index='weekday', columns='city', values='signups')
signups_pivot
|
| city | Austin | Dallas |
|---|
| weekday | | |
|---|
| Mon | 3 | 5 |
|---|
| Sun | 7 | 12 |
|---|
1
2
3
| # Pivot users pivoted by both signups and visitors: pivot
pivot = users.pivot(index='weekday', columns='city')
pivot
|
| visitors | signups |
|---|
| city | Austin | Dallas | Austin | Dallas |
|---|
| weekday | | | | |
|---|
| Mon | 326 | 456 | 3 | 5 |
|---|
| Sun | 139 | 237 | 7 | 12 |
|---|
Notice how in the second DataFrame, both ‘signups’ and ‘visitors’ were pivoted by default since you didn’t provide an argument for the values parameter.
Stacking & unstacking DataFrames
Creating a multi-level index
| id | treatment | gender | response |
|---|
| 0 | 1 | A | F | 5 |
|---|
| 1 | 2 | A | M | 3 |
|---|
| 2 | 3 | B | F | 8 |
|---|
| 3 | 4 | B | M | 9 |
|---|
1
2
| trials = trials.set_index(['treatment', 'gender'])
trials
|
| | id | response |
|---|
| treatment | gender | | |
|---|
| A | F | 1 | 5 |
|---|
| M | 2 | 3 |
|---|
| B | F | 3 | 8 |
|---|
| M | 4 | 9 |
|---|
Unstacking a multi-index (1)
1
| trials.unstack(level='gender')
|
| id | response |
|---|
| gender | F | M | F | M |
|---|
| treatment | | | | |
|---|
| A | 1 | 2 | 5 | 3 |
|---|
| B | 3 | 4 | 8 | 9 |
|---|
Unstacking a multi-index (2)
| | id | response |
|---|
| treatment | gender | | |
|---|
| A | F | 1 | 5 |
|---|
| M | 2 | 3 |
|---|
| B | F | 3 | 8 |
|---|
| M | 4 | 9 |
|---|
1
| trials.unstack(level=1)
|
| id | response |
|---|
| gender | F | M | F | M |
|---|
| treatment | | | | |
|---|
| A | 1 | 2 | 5 | 3 |
|---|
| B | 3 | 4 | 8 | 9 |
|---|
Stacking DataFrames
1
2
| trials_by_gender = trials.unstack(level='gender')
trials_by_gender
|
| id | response |
|---|
| gender | F | M | F | M |
|---|
| treatment | | | | |
|---|
| A | 1 | 2 | 5 | 3 |
|---|
| B | 3 | 4 | 8 | 9 |
|---|
1
| trials_by_gender.stack(level='gender')
|
| | id | response |
|---|
| treatment | gender | | |
|---|
| A | F | 1 | 5 |
|---|
| M | 2 | 3 |
|---|
| B | F | 3 | 8 |
|---|
| M | 4 | 9 |
|---|
1
2
| stacked = trials_by_gender.stack(level='gender')
stacked
|
| | id | response |
|---|
| treatment | gender | | |
|---|
| A | F | 1 | 5 |
|---|
| M | 2 | 3 |
|---|
| B | F | 3 | 8 |
|---|
| M | 4 | 9 |
|---|
Swapping levels
1
2
| swapped = stacked.swaplevel(0, 1)
swapped
|
| | id | response |
|---|
| gender | treatment | | |
|---|
| F | A | 1 | 5 |
|---|
| M | A | 2 | 3 |
|---|
| F | B | 3 | 8 |
|---|
| M | B | 4 | 9 |
|---|
Sorting rows
1
2
| sorted_trials = swapped.sort_index()
sorted_trials
|
| | id | response |
|---|
| gender | treatment | | |
|---|
| F | A | 1 | 5 |
|---|
| B | 3 | 8 |
|---|
| M | A | 2 | 3 |
|---|
| B | 4 | 9 |
|---|
Exercises
Stacking & unstacking I
You are now going to practice stacking and unstacking DataFrames. The users DataFrame you have been working with in this chapter has been pre-loaded for you, this time with a MultiIndex. Explore it in the IPython Shell to see the data layout. Pay attention to the index, and notice that the index levels are [‘city’, ‘weekday’]. So ‘weekday’ - the second entry - has position 1. This position is what corresponds to the level parameter in .stack() and .unstack() calls. Alternatively, you can specify ‘weekday’ as the level instead of its position.
Your job in this exercise is to unstack users by ‘weekday’. You will then use .stack() on the unstacked DataFrame to see if you get back the original layout of users.
Instructions
- Define a DataFrame byweekday with the ‘weekday’ level of users unstacked.
- Print the byweekday DataFrame to see the new data layout. This has been done for you.
- Stack byweekday by ‘weekday’ and print it to check if you get the same layout as the original users DataFrame.
1
2
3
4
| users = pd.read_csv(users_data)
users.set_index(['city', 'weekday'], inplace=True)
users = users.sort_index()
users
|
| | visitors | signups |
|---|
| city | weekday | | |
|---|
| Austin | Mon | 326 | 3 |
|---|
| Sun | 139 | 7 |
|---|
| Dallas | Mon | 456 | 5 |
|---|
| Sun | 237 | 12 |
|---|
1
2
3
| # Unstack users by 'weekday': byweekday
byweekday = users.unstack(level='weekday')
byweekday
|
| visitors | signups |
|---|
| weekday | Mon | Sun | Mon | Sun |
|---|
| city | | | | |
|---|
| Austin | 326 | 139 | 3 | 7 |
|---|
| Dallas | 456 | 237 | 5 | 12 |
|---|
1
2
| # Stack byweekday by 'weekday' and print it
byweekday.stack(level='weekday')
|
| | visitors | signups |
|---|
| city | weekday | | |
|---|
| Austin | Mon | 326 | 3 |
|---|
| Sun | 139 | 7 |
|---|
| Dallas | Mon | 456 | 5 |
|---|
| Sun | 237 | 12 |
|---|
Stacking & unstacking II
You are now going to continue working with the users DataFrame. As always, first explore it in the IPython Shell to see the layout and note the index.
Your job in this exercise is to unstack and then stack the ‘city’ level, as you did previously for ‘weekday’. Note that you won’t get the same DataFrame.
Instructions
- Define a DataFrame bycity with the ‘city’ level of users unstacked.
- Print the bycity DataFrame to see the new data layout. This has been done for you.
- Stack bycity by ‘city’ and print it to check if you get the same layout as the original users DataFrame.
| | visitors | signups |
|---|
| city | weekday | | |
|---|
| Austin | Mon | 326 | 3 |
|---|
| Sun | 139 | 7 |
|---|
| Dallas | Mon | 456 | 5 |
|---|
| Sun | 237 | 12 |
|---|
1
2
3
| # Unstack users by 'city': bycity
bycity = users.unstack(level='city')
bycity
|
| visitors | signups |
|---|
| city | Austin | Dallas | Austin | Dallas |
|---|
| weekday | | | | |
|---|
| Mon | 326 | 456 | 3 | 5 |
|---|
| Sun | 139 | 237 | 7 | 12 |
|---|
1
2
| # Stack bycity by 'city' and print it
bycity.stack(level='city')
|
| | visitors | signups |
|---|
| weekday | city | | |
|---|
| Mon | Austin | 326 | 3 |
|---|
| Dallas | 456 | 5 |
|---|
| Sun | Austin | 139 | 7 |
|---|
| Dallas | 237 | 12 |
|---|
Restoring the index order
Continuing from the previous exercise, you will now use .swaplevel(0, 1) to flip the index levels. Note they won’t be sorted. To sort them, you will have to follow up with a .sort_index(). You will then obtain the original DataFrame. Note that an unsorted index leads to slicing failures.
To begin, print both users and bycity in the IPython Shell. The goal here is to convert bycity back to something that looks like users.
Instructions
- Define a DataFrame newusers with the ‘city’ level stacked back into the index of bycity.
- Swap the levels of the index of newusers.
- Print newusers and verify that the index is not sorted. This has been done for you.
- Sort the index of newusers.
- Print newusers and verify that the index is now sorted. This has been done for you.
- Assert that newusers equals users. This has been done for you, so hit ‘Submit Answer’ to see the result.
| visitors | signups |
|---|
| city | Austin | Dallas | Austin | Dallas |
|---|
| weekday | | | | |
|---|
| Mon | 326 | 456 | 3 | 5 |
|---|
| Sun | 139 | 237 | 7 | 12 |
|---|
1
2
3
| # Stack 'city' back into the index of bycity: newusers
newusers = bycity.stack(level='city')
newusers
|
| | visitors | signups |
|---|
| weekday | city | | |
|---|
| Mon | Austin | 326 | 3 |
|---|
| Dallas | 456 | 5 |
|---|
| Sun | Austin | 139 | 7 |
|---|
| Dallas | 237 | 12 |
|---|
1
2
3
| # Swap the levels of the index of newusers: newusers
newusers = newusers.swaplevel(0, 1)
newusers
|
| | visitors | signups |
|---|
| city | weekday | | |
|---|
| Austin | Mon | 326 | 3 |
|---|
| Dallas | Mon | 456 | 5 |
|---|
| Austin | Sun | 139 | 7 |
|---|
| Dallas | Sun | 237 | 12 |
|---|
1
2
3
| # Sort the index of newusers: newusers
newusers = newusers.sort_index()
newusers
|
| | visitors | signups |
|---|
| city | weekday | | |
|---|
| Austin | Mon | 326 | 3 |
|---|
| Sun | 139 | 7 |
|---|
| Dallas | Mon | 456 | 5 |
|---|
| Sun | 237 | 12 |
|---|
1
2
| # Verify that the new DataFrame is equal to the original
newusers.equals(users)
|
Melting DataFrames
Clinical Trials Data
1
2
3
4
5
6
| trials = pd.DataFrame([[1, 'A', 'F', 5],
[2, 'A', 'M', 3],
[3, 'B', 'F', 8],
[4, 'B', 'M', 9]],
columns=['id', 'treatment', 'gender', 'response'])
trials
|
| id | treatment | gender | response |
|---|
| 0 | 1 | A | F | 5 |
|---|
| 1 | 2 | A | M | 3 |
|---|
| 2 | 3 | B | F | 8 |
|---|
| 3 | 4 | B | M | 9 |
|---|
Clinical trials after pivoting
1
2
3
4
| trials.pivot(index='treatment',
columns='gender',
values='response')
|
Clinical trials data - new
1
2
3
4
| new_trials = pd.DataFrame([['A', 5, 3],
['B', 8, 9],],
columns=['treatment', 'F', 'M'])
new_trials
|
Melting DataFrame
| variable | value |
|---|
| 0 | treatment | A |
|---|
| 1 | treatment | B |
|---|
| 2 | F | 5 |
|---|
| 3 | F | 8 |
|---|
| 4 | M | 3 |
|---|
| 5 | M | 9 |
|---|
Specifying id_vars
1
| pd.melt(new_trials, id_vars=['treatment'])
|
| treatment | variable | value |
|---|
| 0 | A | F | 5 |
|---|
| 1 | B | F | 8 |
|---|
| 2 | A | M | 3 |
|---|
| 3 | B | M | 9 |
|---|
Specifying value_vars
1
2
| pd.melt(new_trials, id_vars=['treatment'],
value_vars=['F', 'M'])
|
| treatment | variable | value |
|---|
| 0 | A | F | 5 |
|---|
| 1 | B | F | 8 |
|---|
| 2 | A | M | 3 |
|---|
| 3 | B | M | 9 |
|---|
Specifying value_name
1
2
| pd.melt(new_trials, id_vars=['treatment'],
var_name='gender', value_name='response')
|
| treatment | gender | response |
|---|
| 0 | A | F | 5 |
|---|
| 1 | B | F | 8 |
|---|
| 2 | A | M | 3 |
|---|
| 3 | B | M | 9 |
|---|
Exercises
Adding names for readability
You are now going to practice melting DataFrames. A DataFrame called visitors_by_city_weekday has been pre-loaded for you. Explore it in the IPython Shell and see that it is the users DataFrame from previous exercises with the rows indexed by ‘weekday’, columns indexed by ‘city’, and values populated with ‘visitors’.
Recall from the video that the goal of melting is to restore a pivoted DataFrame to its original form, or to change it from a wide shape to a long shape. You can explicitly specify the columns that should remain in the reshaped DataFrame with id_vars, and list which columns to convert into values with value_vars. As Dhavide demonstrated, if you don’t pass a name to the values in d.melt(), you will lose the name of your variable. You can fix this by using the value_name keyword argument.
Your job in this exercise is to melt visitors_by_city_weekday to move the city names from the column labels to values in a single column called ‘city’. If you were to use just pd.melt(visitors_by_city_weekday), you would obtain the following result:
1
2
3
4
5
6
7
| city value
0 weekday Mon
1 weekday Sun
2 Austin 326
3 Austin 139
4 Dallas 456
5 Dallas 237
|
Therefore, you have to specify the id_vars keyword argument to ensure that ‘weekday’ is retained in the reshaped DataFrame, and the value_name keyword argument to change the name of value to visitors.
Instructions
- Reset the index of visitors_by_city_weekday with .reset_index().
- Print visitors_by_city_weekday and verify that you have just a range index, 0, 1, 2, 3. This has been done for you.
- Melt visitors_by_city_weekday to move the city names from the column labels to values in a single column called visitors.
- Print visitors to check that the city values are in a single column now and that the dataframe is longer and skinnier.
1
2
3
4
5
| # Create the DataFrame for the exercise
visitors = pd.DataFrame({'weekday': ['Mon', 'Sun', 'Mon', 'Sun'],
'city': ['Austin', 'Austin', 'Dallas', 'Dallas'],
'visitors': [326, 139, 456, 237]})
visitors
|
| weekday | city | visitors |
|---|
| 0 | Mon | Austin | 326 |
|---|
| 1 | Sun | Austin | 139 |
|---|
| 2 | Mon | Dallas | 456 |
|---|
| 3 | Sun | Dallas | 237 |
|---|
1
2
3
4
5
| # Reshape the DataFrame for the exercise
visitors_by_city_weekday = visitors.pivot(index='weekday',
columns='city',
values='visitors')
visitors_by_city_weekday
|
| city | Austin | Dallas |
|---|
| weekday | | |
|---|
| Mon | 326 | 456 |
|---|
| Sun | 139 | 237 |
|---|
1
2
3
| # Reset the index: visitors_by_city_weekday
visitors_by_city_weekday = visitors_by_city_weekday.reset_index()
visitors_by_city_weekday
|
| city | weekday | Austin | Dallas |
|---|
| 0 | Mon | 326 | 456 |
|---|
| 1 | Sun | 139 | 237 |
|---|
1
2
3
| # Melt visitors_by_city_weekday: visitors
visitors = pd.melt(visitors_by_city_weekday, id_vars=['weekday'], value_name='visitors')
visitors
|
| weekday | city | visitors |
|---|
| 0 | Mon | Austin | 326 |
|---|
| 1 | Sun | Austin | 139 |
|---|
| 2 | Mon | Dallas | 456 |
|---|
| 3 | Sun | Dallas | 237 |
|---|
Notice how the melted DataFrame now has a ‘city’ column with Austin and Dallas as its values. In the original DataFrame, they were columns themselves. Also note how specifying the value_name parameter has renamed the ‘value’ column to ‘visitors’.
Going from wide to long
You can move multiple columns into a single column (making the data long and skinny) by “melting” multiple columns. In this exercise, you will practice doing this.
The users DataFrame has been pre-loaded for you. As always, explore it in the IPython Shell and note the index.
Instructions
- Define a DataFrame skinny where you melt the ‘visitors’ and ‘signups’ columns of users into a single column.
- Print skinny to verify the results. Note the value column that had the cell values in users.
1
2
| users = pd.read_csv(users_data)
users
|
| weekday | city | visitors | signups |
|---|
| 0 | Sun | Austin | 139 | 7 |
|---|
| 1 | Sun | Dallas | 237 | 12 |
|---|
| 2 | Mon | Austin | 326 | 3 |
|---|
| 3 | Mon | Dallas | 456 | 5 |
|---|
1
2
3
| # Melt users: skinny
skinny = users.melt(id_vars=['weekday', 'city'])
skinny
|
| weekday | city | variable | value |
|---|
| 0 | Sun | Austin | visitors | 139 |
|---|
| 1 | Sun | Dallas | visitors | 237 |
|---|
| 2 | Mon | Austin | visitors | 326 |
|---|
| 3 | Mon | Dallas | visitors | 456 |
|---|
| 4 | Sun | Austin | signups | 7 |
|---|
| 5 | Sun | Dallas | signups | 12 |
|---|
| 6 | Mon | Austin | signups | 3 |
|---|
| 7 | Mon | Dallas | signups | 5 |
|---|
Because var_name or value_name parameters weren’t specified, the melted DataFrame has the default variable and value column names.
Obtaining key-value pairs with melt()
Sometimes, all you need is some key-value pairs, and the context does not matter. If said context is in the index, you can easily obtain what you want. For example, in the users DataFrame, the visitors and signups columns lend themselves well to being represented as key-value pairs. So if you created a hierarchical index with ‘city’ and ‘weekday’ columns as the index, you can easily extract key-value pairs for the ‘visitors’ and ‘signups’ columns by melting users and specifying col_level=0.
Instructions
- Set the index of users to [‘city’, ‘weekday’].
- Print the DataFrame users_idx to see the new index.
- Obtain the key-value pairs corresponding to visitors and signups by melting users_idx with the keyword argument col_level=0.
| weekday | city | visitors | signups |
|---|
| 0 | Sun | Austin | 139 | 7 |
|---|
| 1 | Sun | Dallas | 237 | 12 |
|---|
| 2 | Mon | Austin | 326 | 3 |
|---|
| 3 | Mon | Dallas | 456 | 5 |
|---|
1
2
3
| # Set the new index: users_idx
users_idx = users.set_index(['city', 'weekday'])
users_idx
|
| | visitors | signups |
|---|
| city | weekday | | |
|---|
| Austin | Sun | 139 | 7 |
|---|
| Dallas | Sun | 237 | 12 |
|---|
| Austin | Mon | 326 | 3 |
|---|
| Dallas | Mon | 456 | 5 |
|---|
1
2
3
| # Obtain the key-value pairs: kv_pairs
kv_pairs = users_idx.melt(col_level=0)
kv_pairs
|
| variable | value |
|---|
| 0 | visitors | 139 |
|---|
| 1 | visitors | 237 |
|---|
| 2 | visitors | 326 |
|---|
| 3 | visitors | 456 |
|---|
| 4 | signups | 7 |
|---|
| 5 | signups | 12 |
|---|
| 6 | signups | 3 |
|---|
| 7 | signups | 5 |
|---|
Pivot tables
More clinical trials data
1
2
3
4
5
6
7
8
9
10
| more_trials = pd.DataFrame([[1, 'A', 'F', 5],
[2, 'A', 'M', 3],
[3, 'A', 'M', 8],
[4, 'A', 'F', 9],
[5, 'B', 'F', 1],
[6, 'B', 'M', 8],
[7, 'B', 'F', 4],
[8, 'B', 'F', 6]],
columns=['id', 'treatment', 'gender', 'response'])
more_trials
|
| id | treatment | gender | response |
|---|
| 0 | 1 | A | F | 5 |
|---|
| 1 | 2 | A | M | 3 |
|---|
| 2 | 3 | A | M | 8 |
|---|
| 3 | 4 | A | F | 9 |
|---|
| 4 | 5 | B | F | 1 |
|---|
| 5 | 6 | B | M | 8 |
|---|
| 6 | 7 | B | F | 4 |
|---|
| 7 | 8 | B | F | 6 |
|---|
Rearranging by pivoting
- .pivot requires unique index/column pairs to identify values in the new table.
1
2
3
4
5
6
| try:
more_trials.pivot(index='treatment',
columns='gender',
values='response')
except ValueError:
print('ValueError: Index contains duplicate entries, cannot reshape')
|
1
| ValueError: Index contains duplicate entries, cannot reshape
|
Pivot table
- The pivot_talbe method reshapes the DataFrame by summarizing it with a pair of summarizing variables and their values.
- Pivot tables deal with multiple values for the same index/column pair using a reduction
- By default, the reduction is an average
1
2
3
| more_trials.pivot_table(index='treatment',
columns='gender',
values='response')
|
| gender | F | M |
|---|
| treatment | | |
|---|
| A | 7.000000 | 5.5 |
|---|
| B | 3.666667 | 8.0 |
|---|
Other aggregations
1
2
3
4
| more_trials.pivot_table(index='treatment',
columns='gender',
values='response',
aggfunc='count')
|
Exercises
Setting up a pivot table
Recall from the video that a pivot table allows you to see all of your variables as a function of two other variables. In this exercise, you will use the .pivot_table() method to see how the users DataFrame entries appear when presented as functions of the ‘weekday’ and ‘city’ columns. That is, with the rows indexed by ‘weekday’ and the columns indexed by ‘city’.
Before using the pivot table, print the users DataFrame in the IPython Shell and observe the layout.
Instructions
- Use a pivot table to index the rows of users by ‘weekday’ and the columns of users by ‘city’. These correspond to the index and columns parameters of .pivot_table().
- Print by_city_day. This has been done for you, so hit ‘Submit Answer’ to see the result.
1
| users = pd.read_csv(users_data)
|
1
2
3
4
| # Create the DataFrame with the appropriate pivot table: by_city_day
by_city_day = users.pivot_table(index='weekday',
columns='city')
by_city_day
|
| signups | visitors |
|---|
| city | Austin | Dallas | Austin | Dallas |
|---|
| weekday | | | | |
|---|
| Mon | 3.0 | 5.0 | 326.0 | 456.0 |
|---|
| Sun | 7.0 | 12.0 | 139.0 | 237.0 |
|---|
Notice the labels of the index and the columns are ‘weekday’ and ‘city’, respectively - exactly as you specified.
Using other aggregations in pivot tables
You can also use aggregation functions within a pivot table by specifying the aggfunc parameter. In this exercise, you will practice using the ‘count’ and len aggregation functions - which produce the same result - on the users DataFrame.
Instructions
- Define a DataFrame count_by_weekday1 that shows the count of each column with the parameter aggfunc=’count’. The index here is ‘weekday’.
- Print count_by_weekday1. This has been done for you.
- Replace aggfunc=’count’ with aggfunc=len and verify you obtain the same result.
1
2
3
4
| # Use a pivot table to display the count of each column: count_by_weekday1
count_by_weekday1 = users.pivot_table(index='weekday',
aggfunc='count')
count_by_weekday1
|
| city | signups | visitors |
|---|
| weekday | | | |
|---|
| Mon | 2 | 2 | 2 |
|---|
| Sun | 2 | 2 | 2 |
|---|
1
2
3
4
| # Replace 'aggfunc='count'' with 'aggfunc=len': count_by_weekday2
count_by_weekday2 = users.pivot_table(index='weekday',
aggfunc=len)
count_by_weekday2
|
| city | signups | visitors |
|---|
| weekday | | | |
|---|
| Mon | 2 | 2 | 2 |
|---|
| Sun | 2 | 2 | 2 |
|---|
1
2
| # Verify that the same result is obtained
count_by_weekday1.equals(count_by_weekday2)
|
Using margins in pivot tables
Sometimes it’s useful to add totals in the margins of a pivot table. You can do this with the argument margins=True. In this exercise, you will practice using margins in a pivot table along with a new aggregation function: sum.
The users DataFrame, which you are now probably very familiar with, has been pre-loaded for you.
Instructions
- Define a DataFrame signups_and_visitors that shows the breakdown of signups and visitors by day.
- You will need to use aggfunc=sum to do this.
- Print signups_and_visitors. This has been done for you.
- Now pass the additional argument margins=True to the .pivot_table() method to obtain the totals.
- Print signups_and_visitors_total. This has been done for you, so hit ‘Submit Answer’ to see the result.
1
2
3
4
| # Create the DataFrame with the appropriate pivot table: signups_and_visitors
signups_and_visitors = users.pivot_table(index='weekday',
aggfunc='sum')
signups_and_visitors
|
| city | signups | visitors |
|---|
| weekday | | | |
|---|
| Mon | AustinDallas | 8 | 782 |
|---|
| Sun | AustinDallas | 19 | 376 |
|---|
1
2
3
4
5
6
| # Add in the margins: signups_and_visitors_total
signups_and_visitors_total = users.pivot_table(index='weekday',
values=['signups', 'visitors'],
aggfunc='sum',
margins=True)
signups_and_visitors_total
|
| signups | visitors |
|---|
| weekday | | |
|---|
| Mon | 8 | 782 |
|---|
| Sun | 19 | 376 |
|---|
| All | 27 | 1158 |
|---|
Specifying margins=True resulted in the totals in each column being computed.
Grouping data
In this chapter, you’ll learn how to identify and split DataFrames by groups or categories for further aggregation or analysis. You’ll also learn how to transform and filter your data, including how to detect outliers and impute missing values. Knowing how to effectively group data in pandas can be a seriously powerful addition to your data science toolbox.
Categorical and groupby
Sales Data
1
2
3
4
5
6
7
8
9
| sales = pd.DataFrame(
{
'weekday': ['Sun', 'Sun', 'Mon', 'Mon'],
'city': ['Austin', 'Dallas', 'Austin', 'Dallas'],
'bread': [139, 237, 326, 456],
'butter': [20, 45, 70, 98]
}
)
sales
|
| weekday | city | bread | butter |
|---|
| 0 | Sun | Austin | 139 | 20 |
|---|
| 1 | Sun | Dallas | 237 | 45 |
|---|
| 2 | Mon | Austin | 326 | 70 |
|---|
| 3 | Mon | Dallas | 456 | 98 |
|---|
Boolean filter and count
1
| sales.loc[sales['weekday'] == 'Sun'].count()
|
1
2
3
4
5
| weekday 2
city 2
bread 2
butter 2
dtype: int64
|
Groupby and count
1
| sales.groupby('weekday').count()
|
| city | bread | butter |
|---|
| weekday | | | |
|---|
| Mon | 2 | 2 | 2 |
|---|
| Sun | 2 | 2 | 2 |
|---|
Split-apply-combine
- sales.groupby(‘weekday’).count()
- split by ‘weekday’
- apply count() function on each group
- combine counts per group
Aggregation/Reduction
- Some reducing functions
- mean()
- std()
- sum()
- first(), last()
- min(), max()
Groupby and sum
1
| sales.groupby('weekday')['bread'].sum()
|
1
2
3
4
| weekday
Mon 782
Sun 376
Name: bread, dtype: int64
|
Groupby and sum: multiple columns
| weekday | city | bread | butter |
|---|
| 0 | Sun | Austin | 139 | 20 |
|---|
| 1 | Sun | Dallas | 237 | 45 |
|---|
| 2 | Mon | Austin | 326 | 70 |
|---|
| 3 | Mon | Dallas | 456 | 98 |
|---|
1
| sales.groupby('weekday')[['bread','butter']].sum()
|
| bread | butter |
|---|
| weekday | | |
|---|
| Mon | 782 | 168 |
|---|
| Sun | 376 | 65 |
|---|
Groupby and mean: multi-level index
1
| sales.groupby(['city','weekday']).mean()
|
| | bread | butter |
|---|
| city | weekday | | |
|---|
| Austin | Mon | 326.0 | 70.0 |
|---|
| Sun | 139.0 | 20.0 |
|---|
| Dallas | Mon | 456.0 | 98.0 |
|---|
| Sun | 237.0 | 45.0 |
|---|
Customers
1
2
| customers = pd.Series(['Dave','Alice','Bob','Alice'])
customers
|
1
2
3
4
5
| 0 Dave
1 Alice
2 Bob
3 Alice
dtype: object
|
Groupby and sum: by series
1
| sales.groupby(customers)['bread'].sum()
|
1
2
3
4
| Alice 693
Bob 326
Dave 139
Name: bread, dtype: int64
|
Categorical data
1
| sales['weekday'].unique()
|
1
| array(['Sun', 'Mon'], dtype=object)
|
1
2
| sales['weekday'] = sales['weekday'].astype('category')
sales['weekday']
|
1
2
3
4
5
6
| 0 Sun
1 Sun
2 Mon
3 Mon
Name: weekday, dtype: category
Categories (2, object): ['Mon', 'Sun']
|
Categorical data
- Advantages
- Use less memory
- Speeds up operations like
groupby()
Exercises
Advantages of categorical data types
What are the main advantages of storing data explicitly as categorical types instead of object types?
Answer the question
- Computations are faster.
- Categorical data require less space in memory.
- All of the above.
Grouping by multiple columns
In this exercise, you will return to working with the Titanic dataset from Chapter 1 and use .groupby() to analyze the distribution of passengers who boarded the Titanic.
The ‘pclass’ column identifies which class of ticket was purchased by the passenger and the ‘embarked’ column indicates at which of the three ports the passenger boarded the Titanic. ‘S’ stands for Southampton, England, ‘C’ for Cherbourg, France and ‘Q’ for Queenstown, Ireland.
Your job is to first group by the ‘pclass’ column and count the number of rows in each class using the ‘survived’ column. You will then group by the ‘embarked’ and ‘pclass’ columns and count the number of passengers.
The DataFrame has been pre-loaded as titanic.
Instructions
- Group by the ‘pclass’ column and save the result as by_class.
- Aggregate the ‘survived’ column of by_class using .count(). Save the result as count_by_class.
- Print count_by_class. This has been done for you.
- Group titanic by the ‘embarked’ and ‘pclass’ columns. Save the result as by_mult.
- Aggregate the ‘survived’ column of by_mult using .count(). Save the result as count_mult.
- Print count_mult. This has been done for you, so hit ‘Submit Answer’ to view the result.
Titanic Data
1
2
| titanic = pd.read_csv(titanic_data)
titanic.head(3)
|
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest |
|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.00 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
|---|
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.92 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
|---|
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2.00 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
|---|
1
2
3
4
5
6
| # Group titanic by 'pclass'
by_class = titanic.groupby('pclass')
# Aggregate 'survived' column of by_class by count
count_by_class = by_class['survived'].count()
count_by_class
|
1
2
3
4
5
| pclass
1 323
2 277
3 709
Name: survived, dtype: int64
|
1
2
3
4
5
6
| # Group titanic by 'embarked' and 'pclass'
by_mult = titanic.groupby(['embarked', 'pclass'])
# Aggregate 'survived' column of by_mult by count
count_mult = by_mult['survived'].count()
count_mult
|
1
2
3
4
5
6
7
8
9
10
11
| embarked pclass
C 1 141
2 28
3 101
Q 1 3
2 7
3 113
S 1 177
2 242
3 495
Name: survived, dtype: int64
|
Grouping data by certain columns and aggregating them by another column, in this case, ‘survived’, allows for carefull examination of the data for interesting insights.
Grouping by another series
In this exercise, you’ll use two data sets from Gapminder.org to investigate the average life expectancy (in years) at birth in 2010 for the 6 continental regions. To do this you’ll read the life expectancy data per country into one pandas DataFrame and the association between country and region into another.
By setting the index of both DataFrames to the country name, you’ll then use the region information to group the countries in the life expectancy DataFrame and compute the mean value for 2010.
The life expectancy CSV file is available to you in the variable life_fname and the regions filename is available in the variable regions_fname.
Instructions
- Read life_fname into a DataFrame called life and set the index to ‘Country’.
- Read regions_fname into a DataFrame called regions and set the index to ‘Country’.
- Group life by the region column of regions and store the result in life_by_region.
- Print the mean over the 2010 column of life_by_region.
1
2
3
4
5
6
| # Read life_fname into a DataFrame: life
life = pd.read_csv(gapminder_data, usecols=['Year', 'life', 'Country'])
life = life.pivot(index='Country',
columns='Year',
values='life')
life.head()
|
| Year | 1964 | 1965 | 1966 | 1967 | 1968 | 1969 | 1970 | 1971 | 1972 | 1973 | 1974 | 1975 | 1976 | 1977 | 1978 | 1979 | 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 |
|---|
| Country | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
|---|
| Afghanistan | 33.639 | 34.152 | 34.662 | 35.170 | 35.674 | 36.172 | 36.663 | 37.143 | 37.614 | 38.075 | 38.529 | 38.977 | 39.417 | 39.855 | 40.298 | 40.756 | 41.242 | 41.770 | 42.347 | 42.977 | 43.661 | 44.400 | 45.192 | 46.024 | 46.880 | 47.744 | 48.601 | 49.439 | 50.247 | 51.017 | 51.738 | 52.400 | 52.995 | 53.527 | 54.009 | 54.449 | 54.863 | 55.271 | 55.687 | 56.122 | 56.583 | 57.071 | 57.582 | 58.102 | 58.618 | 59.124 | 59.612 | 60.079 | 60.524 | 60.947 |
|---|
| Albania | 65.475 | 65.863 | 66.122 | 66.316 | 66.500 | 66.702 | 66.948 | 67.251 | 67.595 | 67.966 | 68.356 | 68.748 | 69.121 | 69.459 | 69.753 | 70.001 | 70.218 | 70.426 | 70.646 | 70.886 | 71.144 | 71.398 | 71.615 | 71.770 | 71.853 | 71.870 | 71.842 | 71.799 | 71.779 | 71.813 | 71.920 | 72.117 | 72.415 | 72.796 | 73.235 | 73.713 | 74.200 | 74.664 | 75.081 | 75.437 | 75.725 | 75.949 | 76.124 | 76.278 | 76.433 | 76.598 | 76.780 | 76.979 | 77.185 | 77.392 |
|---|
| Algeria | 47.953 | 48.389 | 48.806 | 49.205 | 49.592 | 49.976 | 50.366 | 50.767 | 51.195 | 51.670 | 52.213 | 52.861 | 53.656 | 54.605 | 55.697 | 56.907 | 58.198 | 59.524 | 60.826 | 62.051 | 63.160 | 64.120 | 64.911 | 65.554 | 66.072 | 66.479 | 66.796 | 67.049 | 67.265 | 67.468 | 67.674 | 67.893 | 68.123 | 68.350 | 68.565 | 68.769 | 68.963 | 69.149 | 69.330 | 69.508 | 69.682 | 69.854 | 70.020 | 70.180 | 70.332 | 70.477 | 70.615 | 70.747 | 70.874 | 71.000 |
|---|
| Angola | 34.604 | 35.007 | 35.410 | 35.816 | 36.222 | 36.627 | 37.032 | 37.439 | 37.846 | 38.247 | 38.635 | 38.998 | 39.324 | 39.605 | 39.840 | 40.029 | 40.182 | 40.311 | 40.429 | 40.547 | 40.671 | 40.794 | 40.902 | 40.988 | 41.050 | 41.100 | 41.151 | 41.221 | 41.329 | 41.495 | 41.736 | 42.073 | 42.526 | 43.088 | 43.742 | 44.468 | 45.234 | 46.004 | 46.743 | 47.425 | 48.036 | 48.572 | 49.041 | 49.471 | 49.882 | 50.286 | 50.689 | 51.094 | 51.498 | 51.899 |
|---|
| Antigua and Barbuda | 63.775 | 64.149 | 64.511 | 64.865 | 65.213 | 65.558 | 65.898 | 66.232 | 66.558 | 66.875 | 67.181 | 67.479 | 67.768 | 68.051 | 68.328 | 68.602 | 68.873 | 69.141 | 69.408 | 69.671 | 69.931 | 70.186 | 70.435 | 70.675 | 70.907 | 71.132 | 71.351 | 71.568 | 71.783 | 72.000 | 72.219 | 72.441 | 72.664 | 72.888 | 73.110 | 73.329 | 73.544 | 73.755 | 73.960 | 74.160 | 74.355 | 74.544 | 74.729 | 74.910 | 75.087 | 75.263 | 75.437 | 75.610 | 75.783 | 75.954 |
|---|
1
2
3
4
5
| regions = pd.read_csv(gapminder_data, usecols=['region', 'Country'])
regions.drop_duplicates(subset='Country', inplace=True)
regions.reset_index(inplace=True, drop=True)
regions.set_index('Country', inplace=True)
regions.head()
|
| region |
|---|
| Country | |
|---|
| Afghanistan | South Asia |
|---|
| Albania | Europe & Central Asia |
|---|
| Algeria | Middle East & North Africa |
|---|
| Angola | Sub-Saharan Africa |
|---|
| Antigua and Barbuda | America |
|---|
1
2
3
4
5
| # Group life by regions['region']: life_by_region
life_by_region = life.groupby(regions['region'])
# Print the mean over the '2010' column of life_by_region
life_by_region[2010].mean()
|
1
2
3
4
5
6
7
8
| region
America 74.037350
East Asia & Pacific 73.405750
Europe & Central Asia 75.656387
Middle East & North Africa 72.805333
South Asia 68.189750
Sub-Saharan Africa 57.575080
Name: 2010, dtype: float64
|
| Year | 1964 | 1965 | 1966 | 1967 | 1968 | 1969 | 1970 | 1971 | 1972 | 1973 | 1974 | 1975 | 1976 | 1977 | 1978 | 1979 | 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 |
|---|
| region | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
|---|
| America | 60.462775 | 60.890525 | 61.305125 | 61.720225 | 62.110625 | 62.510550 | 62.907500 | 63.304725 | 63.680025 | 64.060075 | 64.439125 | 64.820550 | 65.194375 | 65.563725 | 65.926700 | 66.293975 | 66.642225 | 67.005425 | 67.356675 | 67.701150 | 68.038475 | 68.356175 | 68.669950 | 68.977200 | 69.263125 | 69.543050 | 69.816700 | 70.069550 | 70.328450 | 70.539900 | 70.775700 | 70.989950 | 71.221100 | 71.459000 | 71.681525 | 71.902925 | 72.147375 | 72.369850 | 72.607250 | 72.840450 | 73.082250 | 73.315275 | 73.564875 | 73.786750 | 74.005625 | 74.241025 | 74.037350 | 74.615275 | 74.883000 | 75.087350 |
|---|
| East Asia & Pacific | 56.798429 | 57.171681 | 57.640694 | 58.313566 | 58.732569 | 59.215162 | 59.586869 | 59.976168 | 60.258246 | 60.489806 | 60.718175 | 60.664653 | 60.902886 | 61.262667 | 61.703322 | 62.172261 | 62.745599 | 63.458618 | 64.057063 | 64.587656 | 65.099125 | 65.468469 | 65.851906 | 66.191781 | 66.493750 | 66.830281 | 67.170781 | 67.519031 | 67.802656 | 68.108937 | 68.398969 | 68.653688 | 68.950875 | 69.280875 | 69.627938 | 69.945969 | 70.346750 | 70.715500 | 71.079750 | 71.432312 | 71.767687 | 72.072219 | 72.284303 | 72.656563 | 72.901188 | 73.163656 | 73.405750 | 73.628875 | 73.855219 | 74.077719 |
|---|
| Europe & Central Asia | 67.840110 | 67.991738 | 68.227918 | 68.455299 | 68.595399 | 68.602929 | 68.880064 | 69.079643 | 69.370631 | 69.539966 | 69.735132 | 69.803467 | 69.976190 | 70.213290 | 70.308209 | 70.474220 | 70.556464 | 70.750901 | 71.003353 | 71.076755 | 71.277763 | 71.417893 | 71.792450 | 71.928528 | 72.010999 | 72.047589 | 72.006429 | 71.993153 | 72.057192 | 71.974376 | 72.106339 | 72.230357 | 72.621081 | 73.005398 | 73.281570 | 73.419375 | 73.731621 | 73.989544 | 74.184069 | 74.365403 | 74.695499 | 74.853989 | 75.128260 | 75.178045 | 75.337358 | 75.491294 | 75.656387 | 75.813836 | 75.961039 | 76.108157 |
|---|
| Middle East & North Africa | 52.119810 | 52.808000 | 53.485714 | 54.153476 | 54.812476 | 55.463952 | 56.112048 | 56.762476 | 57.417381 | 58.076286 | 58.735333 | 59.385476 | 60.014762 | 60.615143 | 61.183905 | 61.723476 | 62.244190 | 62.762048 | 63.290571 | 63.849714 | 64.415952 | 64.996000 | 65.551762 | 66.117429 | 66.651952 | 67.160952 | 67.622286 | 68.012238 | 68.368190 | 68.730524 | 69.052238 | 69.340619 | 69.642143 | 69.894857 | 70.149952 | 70.402286 | 70.643143 | 70.888381 | 71.106000 | 71.333048 | 71.559143 | 71.761714 | 71.975667 | 72.175714 | 72.389190 | 72.598476 | 72.805333 | 72.994333 | 73.100143 | 73.259143 |
|---|
| South Asia | 43.877125 | 44.442500 | 44.976000 | 45.470625 | 45.927000 | 46.354625 | 46.775375 | 47.218250 | 47.707625 | 48.256125 | 48.865625 | 49.525750 | 50.216750 | 50.910125 | 51.582375 | 52.223250 | 52.826250 | 53.392375 | 53.933875 | 54.462375 | 54.983750 | 55.505500 | 56.034625 | 56.574125 | 57.124250 | 57.683875 | 58.247125 | 58.803625 | 59.346125 | 59.870750 | 60.379750 | 60.881500 | 61.390000 | 61.915375 | 62.463000 | 63.030375 | 63.609250 | 64.187750 | 64.750250 | 65.284875 | 65.785625 | 66.250000 | 66.679500 | 67.082625 | 67.466500 | 67.834500 | 68.189750 | 68.533250 | 68.865875 | 69.188000 |
|---|
| Sub-Saharan Africa | 43.579360 | 43.945520 | 44.361380 | 44.687180 | 45.005120 | 45.396420 | 46.041180 | 46.590420 | 47.056080 | 47.484920 | 47.912540 | 48.400680 | 48.944720 | 49.391800 | 49.831660 | 50.277220 | 50.693020 | 51.089080 | 51.462440 | 51.798600 | 52.049780 | 52.249220 | 52.612520 | 52.871120 | 53.052140 | 53.197360 | 53.304860 | 53.359420 | 53.369280 | 53.345320 | 52.526540 | 53.174680 | 53.164150 | 53.153460 | 53.155990 | 53.187740 | 53.271030 | 53.427420 | 53.660240 | 53.977360 | 54.376740 | 54.849940 | 55.381720 | 55.945100 | 56.513780 | 57.069820 | 57.575080 | 57.994060 | 58.514640 | 58.941440 |
|---|
1
2
3
| life_by_region[[1964, 1970, 1980, 1990, 2000, 2010, 2013]].mean().plot(rot=45)
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
plt.show()
|
Groupby and aggregation
Sales data
| weekday | city | bread | butter |
|---|
| 0 | Sun | Austin | 139 | 20 |
|---|
| 1 | Sun | Dallas | 237 | 45 |
|---|
| 2 | Mon | Austin | 326 | 70 |
|---|
| 3 | Mon | Dallas | 456 | 98 |
|---|
Review: groupby
1
| sales.groupby('city')[['bread','butter']].max()
|
| bread | butter |
|---|
| city | | |
|---|
| Austin | 326 | 70 |
|---|
| Dallas | 456 | 98 |
|---|
Multiple aggregations
1
| sales.groupby('city')[['bread','butter']].agg(['max','sum'])
|
| bread | butter |
|---|
| max | sum | max | sum |
|---|
| city | | | | |
|---|
| Austin | 326 | 465 | 70 | 90 |
|---|
| Dallas | 456 | 693 | 98 | 143 |
|---|
Aggregation functions
Custom aggregation
1
2
| def data_range(series):
return series.max() - series.min()
|
1
| sales.groupby('weekday', observed=False)[['bread', 'butter']].agg(data_range)
|
| bread | butter |
|---|
| weekday | | |
|---|
| Mon | 130 | 28 |
|---|
| Sun | 98 | 25 |
|---|
Custom aggregation: dictionaries
1
| sales.groupby(customers)[['bread', 'butter']].agg({'bread':'sum', 'butter':data_range})
|
| bread | butter |
|---|
| Alice | 693 | 53 |
|---|
| Bob | 326 | 0 |
|---|
| Dave | 139 | 0 |
|---|
Exercises
Computing multiple aggregates of multiple columns
The .agg() method can be used with a tuple or list of aggregations as input. When applying multiple aggregations on multiple columns, the aggregated DataFrame has a multi-level column index.
In this exercise, you’re going to group passengers on the Titanic by ‘pclass’ and aggregate the ‘age’ and ‘fare’ columns by the functions ‘max’ and ‘median’. You’ll then use multi-level selection to find the oldest passenger per class and the median fare price per class.
The DataFrame has been pre-loaded as titanic.
Instructions
- Group titanic by ‘pclass’ and save the result as by_class.
- Select the ‘age’ and ‘fare’ columns from by_class and save the result as by_class_sub.
- Aggregate by_class_sub using ‘max’ and ‘median’. You’ll have to pass ‘max’ and ‘median’ in the form of a list to .agg().
- Use .loc[] to print all of the rows and the column specification (‘age’,’max’). This has been done for you.
- Use .loc[] to print all of the rows and the column specification (‘fare’,’median’).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # Group titanic by 'pclass': by_class
by_class = titanic.groupby('pclass')
# Select 'age' and 'fare'
by_class_sub = by_class[['age','fare']]
# Aggregate by_class_sub by 'max' and 'median': aggregated
aggregated = by_class_sub.agg(['max', 'median'])
print(aggregated)
# Print the maximum age in each class
print('\nMaximum Age:\n', aggregated.loc[:, ('age','max')])
# Print the median fare in each class
print('\nMedian Fare:\n', aggregated.loc[:, ('fare','median')])
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| age fare
max median max median
pclass
1 80.0 39.0 512.3292 60.0000
2 70.0 29.0 73.5000 15.0458
3 74.0 24.0 69.5500 8.0500
Maximum Age:
pclass
1 80.0
2 70.0
3 74.0
Name: (age, max), dtype: float64
Median Fare:
pclass
1 60.0000
2 15.0458
3 8.0500
Name: (fare, median), dtype: float64
|
Aggregating on index levels/fields
If you have a DataFrame with a multi-level row index, the individual levels can be used to perform the groupby. This allows advanced aggregation techniques to be applied along one or more levels in the index and across one or more columns.
In this exercise you’ll use the full Gapminder dataset which contains yearly values of life expectancy, population, child mortality (per 1,000) and per capita gross domestic product (GDP) for every country in the world from 1964 to 2013.
Your job is to create a multi-level DataFrame of the columns ‘Year’, ‘Region’ and ‘Country’. Next you’ll group the DataFrame by the ‘Year’ and ‘Region’ levels. Finally, you’ll apply a dictionary aggregation to compute the total population, spread of per capita GDP values and average child mortality rate.
The Gapminder CSV file is available as ‘gapminder.csv’.
Instructions
- Read ‘gapminder.csv’ into a DataFrame with index_col=[‘Year’,’region’,’Country’]. Sort the index.
- Group gapminder with a level of [‘Year’,’region’] using its level parameter. Save the result as by_year_region.
- Define the function spread which returns the maximum and minimum of an input series. This has been done for you.
- Create a dictionary with ‘population’:’sum’, ‘child_mortality’:’mean’ and ‘gdp’:spread as aggregator. This has been done for you.
- Use the aggregator dictionary to aggregate by_year_region. Save the result as aggregated.
- Print the last 6 entries of aggregated. This has been done for you, so hit ‘Submit Answer’ to view the result.
1
2
3
4
| # Read the CSV file into a DataFrame and sort the index: gapminder
gapminder = pd.read_csv(gapminder_data, index_col=['Year', 'region', 'Country'])
gapminder.sort_index(inplace=True)
gapminder.head()
|
| | | fertility | life | population | child_mortality | gdp |
|---|
| Year | region | Country | | | | | |
|---|
| 1964 | America | Antigua and Barbuda | 4.250 | 63.775 | 58653.0 | 72.78 | 5008.0 |
|---|
| Argentina | 3.068 | 65.388 | 21966478.0 | 57.43 | 8227.0 |
|---|
| Aruba | 4.059 | 67.113 | 57031.0 | NaN | 5505.0 |
|---|
| Bahamas | 4.220 | 64.189 | 133709.0 | 48.56 | 18160.0 |
|---|
| Barbados | 4.094 | 62.819 | 234455.0 | 64.70 | 5681.0 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
| # Group gapminder by 'Year' and 'region': by_year_region
by_year_region = gapminder.groupby(level=['Year', 'region'])
# Define the function to compute spread: spread
def spread(series):
return series.max() - series.min()
# Create the dictionary: aggregator
aggregator = {'population':'sum', 'child_mortality':'mean', 'gdp':spread}
# Aggregate by_year_region using the dictionary: aggregated
aggregated = by_year_region.agg(aggregator)
aggregated.tail(6)
|
| | population | child_mortality | gdp |
|---|
| Year | region | | | |
|---|
| 2013 | America | 9.629087e+08 | 17.745833 | 49634.0 |
|---|
| East Asia & Pacific | 2.244209e+09 | 22.285714 | 134744.0 |
|---|
| Europe & Central Asia | 8.968788e+08 | 9.831875 | 86418.0 |
|---|
| Middle East & North Africa | 4.030504e+08 | 20.221500 | 128676.0 |
|---|
| South Asia | 1.701241e+09 | 46.287500 | 11469.0 |
|---|
| Sub-Saharan Africa | 9.205996e+08 | 76.944490 | 32035.0 |
|---|
Grouping on a function of the index
Groupby operations can also be performed on transformations of the index values. In the case of a DateTimeIndex, we can extract portions of the datetime over which to group.
In this exercise you’ll read in a set of sample sales data from February 2015 and assign the ‘Date’ column as the index. Your job is to group the sales data by the day of the week and aggregate the sum of the ‘Units’ column.
Is there a day of the week that is more popular for customers? To find out, you’re going to use .strftime(‘%a’) to transform the index datetime values to abbreviated days of the week.
The sales data CSV file is available to you as ‘sales.csv’.
Instructions
- Read ‘sales.csv’ into a DataFrame with index_col=’Date’ and parse_dates=True.
- Create a groupby object with sales.index.strftime(‘%a’) as input and assign it to by_day.
- Aggregate the ‘Units’ column of by_day with the .sum() method. Save the result as units_sum.
- Print units_sum. This has been done for you, so hit ‘Submit Answer’ to see the result.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| sales_values = np.array([['2015-02-02 08:30:00', 'Hooli', 'Software', 3],
['2015-02-02 21:00:00', 'Mediacore', 'Hardware', 9],
['2015-02-03 14:00:00', 'Initech', 'Software', 13],
['2015-02-04 15:30:00', 'Streeplex', 'Software', 13],
['2015-02-04 22:00:00', 'Acme Coporation', 'Hardware', 14],
['2015-02-05 02:00:00', 'Acme Coporation', 'Software', 19],
['2015-02-05 22:00:00', 'Hooli', 'Service', 10],
['2015-02-07 23:00:00', 'Acme Coporation', 'Hardware', 1],
['2015-02-09 09:00:00', 'Streeplex', 'Service', 19],
['2015-02-09 13:00:00', 'Mediacore', 'Software', 7],
['2015-02-11 20:00:00', 'Initech', 'Software', 7],
['2015-02-11 23:00:00', 'Hooli', 'Software', 4],
['2015-02-16 12:00:00', 'Hooli', 'Software', 10],
['2015-02-19 11:00:00', 'Mediacore', 'Hardware', 16],
['2015-02-19 16:00:00', 'Mediacore', 'Service', 10],
['2015-02-21 05:00:00', 'Mediacore', 'Software', 3],
['2015-02-21 20:30:00', 'Hooli', 'Hardware', 3],
['2015-02-25 00:30:00', 'Initech', 'Service', 10],
['2015-02-26 09:00:00', 'Streeplex', 'Service', 4]])
sales_cols = ['Date', 'Company', 'Product', 'Units']
|
1
2
3
4
5
| sales = pd.DataFrame(sales_values, columns=sales_cols)
sales['Date'] = pd.to_datetime(sales['Date'])
sales.set_index('Date', inplace=True)
sales['Units'] = sales['Units'].astype('int64')
sales.head()
|
| Company | Product | Units |
|---|
| Date | | | |
|---|
| 2015-02-02 08:30:00 | Hooli | Software | 3 |
|---|
| 2015-02-02 21:00:00 | Mediacore | Hardware | 9 |
|---|
| 2015-02-03 14:00:00 | Initech | Software | 13 |
|---|
| 2015-02-04 15:30:00 | Streeplex | Software | 13 |
|---|
| 2015-02-04 22:00:00 | Acme Coporation | Hardware | 14 |
|---|
1
2
3
4
5
6
7
8
9
10
| <class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 19 entries, 2015-02-02 08:30:00 to 2015-02-26 09:00:00
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Company 19 non-null object
1 Product 19 non-null object
2 Units 19 non-null int64
dtypes: int64(1), object(2)
memory usage: 608.0+ bytes
|
1
2
3
4
5
6
| # Create a groupby object: by_day
by_day = sales.groupby(sales.index.strftime('%a'))
# Create sum: units_sum
units_sum = by_day['Units'].sum()
units_sum
|
1
2
3
4
5
6
7
| Date
Mon 48
Sat 7
Thu 59
Tue 13
Wed 48
Name: Units, dtype: int64
|
The z-score
1
2
| def zscore_def(series):
return (series - series.mean()) / series.std()
|
The automobile dataset
1
2
| auto = pd.read_csv(auto_mpg)
auto.head()
|
| mpg | cyl | displ | hp | weight | accel | yr | origin | name |
|---|
| 0 | 18.0 | 8 | 307.0 | 130 | 3504 | 12.0 | 70 | US | chevrolet chevelle malibu |
|---|
| 1 | 15.0 | 8 | 350.0 | 165 | 3693 | 11.5 | 70 | US | buick skylark 320 |
|---|
| 2 | 18.0 | 8 | 318.0 | 150 | 3436 | 11.0 | 70 | US | plymouth satellite |
|---|
| 3 | 16.0 | 8 | 304.0 | 150 | 3433 | 12.0 | 70 | US | amc rebel sst |
|---|
| 4 | 17.0 | 8 | 302.0 | 140 | 3449 | 10.5 | 70 | US | ford torino |
|---|
MPG z-score
1
| zscore_def(auto['mpg']).head()
|
1
2
3
4
5
6
| 0 -0.697747
1 -1.082115
2 -0.697747
3 -0.953992
4 -0.825870
Name: mpg, dtype: float64
|
1
2
| # imported from scipy at the top
zscore(auto['mpg'])[:5]
|
1
2
3
4
5
6
| 0 -0.698638
1 -1.083498
2 -0.698638
3 -0.955212
4 -0.826925
Name: mpg, dtype: float64
|
MPG z-score by year
1
| auto.groupby('yr')['mpg'].transform(zscore_def).head()
|
1
2
3
4
5
6
| 0 0.058125
1 -0.503753
2 0.058125
3 -0.316460
4 -0.129168
Name: mpg, dtype: float64
|
1
2
3
4
5
6
| def zscore_with_year_and_name(group):
df = pd.DataFrame(
{'mpg': zscore(group['mpg']),
'year': group['yr'],
'name': group['name']})
return df
|
1
| auto.groupby('yr').apply(zscore_with_year_and_name).head()
|
| | mpg | year | name |
|---|
| yr | | | | |
|---|
| 70 | 0 | 0.059154 | 70 | chevrolet chevelle malibu |
|---|
| 1 | -0.512670 | 70 | buick skylark 320 |
|---|
| 2 | 0.059154 | 70 | plymouth satellite |
|---|
| 3 | -0.322062 | 70 | amc rebel sst |
|---|
| 4 | -0.131454 | 70 | ford torino |
|---|
Exercises
Detecting outliers with Z-Scores
As Dhavide demonstrated in the video using the zscore function, you can apply a .transform() method after grouping to apply a function to groups of data independently. The z-score is also useful to find outliers: a z-score value of +/- 3 is generally considered to be an outlier.
In this example, you’re going to normalize the Gapminder data in 2010 for life expectancy and fertility by the z-score per region. Using boolean indexing, you will filter out countries that have high fertility rates and low life expectancy for their region.
The Gapminder DataFrame for 2010 indexed by ‘Country’ is provided for you as gapminder_2010.
Instructions
- Import zscore from scipy.stats.
- Group gapminder_2010 by ‘region’ and transform the [‘life’,’fertility’] columns by zscore.
- Construct a boolean Series of the bitwise or between standardized[‘life’] < -3 and standardized[‘fertility’] > 3.
- Filter gapminder_2010 using .loc[] and the outliers Boolean Series. Save the result as gm_outliers.
- Print gm_outliers. This has been done for you, so hit ‘Submit Answer’ to see the results.
1
2
3
4
5
| gapminder = pd.read_csv(gapminder_data, index_col='Country')
gapminder_mask = gapminder['Year'] == 2010
gapminder_2010 = gapminder[gapminder_mask].copy()
gapminder_2010.drop('Year', axis=1, inplace=True)
gapminder_2010.head()
|
| fertility | life | population | child_mortality | gdp | region |
|---|
| Country | | | | | | |
|---|
| Afghanistan | 5.659 | 59.612 | 31411743.0 | 105.0 | 1637.0 | South Asia |
|---|
| Albania | 1.741 | 76.780 | 3204284.0 | 16.6 | 9374.0 | Europe & Central Asia |
|---|
| Algeria | 2.817 | 70.615 | 35468208.0 | 27.4 | 12494.0 | Middle East & North Africa |
|---|
| Angola | 6.218 | 50.689 | 19081912.0 | 182.5 | 7047.0 | Sub-Saharan Africa |
|---|
| Antigua and Barbuda | 2.130 | 75.437 | 88710.0 | 9.9 | 20567.0 | America |
|---|
1
2
3
| # Group gapminder_2010: standardized
standardized = gapminder_2010.groupby('region')[['life', 'fertility']].transform(zscore)
standardized.head()
|
| life | fertility |
|---|
| Country | | |
|---|
| Afghanistan | -1.743601 | 2.504732 |
|---|
| Albania | 0.226367 | 0.010964 |
|---|
| Algeria | -0.440196 | -0.003972 |
|---|
| Angola | -0.882537 | 1.095653 |
|---|
| Antigua and Barbuda | 0.240607 | -0.363761 |
|---|
1
2
3
4
5
6
| # Construct a Boolean Series to identify outliers: outliers
outliers = (standardized['life'] < -3) | (standardized['fertility'] > 3)
# Filter gapminder_2010 by the outliers: gm_outliers
gm_outliers = gapminder_2010.loc[outliers]
gm_outliers
|
| fertility | life | population | child_mortality | gdp | region |
|---|
| Country | | | | | | |
|---|
| Guatemala | 3.974 | 71.100 | 14388929.0 | 34.5 | 6849.0 | America |
|---|
| Haiti | 3.350 | 45.000 | 9993247.0 | 208.8 | 1518.0 | America |
|---|
| Tajikistan | 3.780 | 66.830 | 6878637.0 | 52.6 | 2110.0 | Europe & Central Asia |
|---|
| Timor-Leste | 6.237 | 65.952 | 1124355.0 | 63.8 | 1777.0 | East Asia & Pacific |
|---|
Filling missing data (imputation) by group
Many statistical and machine learning packages cannot determine the best action to take when missing data entries are encountered. Dealing with missing data is natural in pandas (both in using the default behavior and in defining a custom behavior). In Chapter 1, you practiced using the .dropna() method to drop missing values. Now, you will practice imputing missing values. You can use .groupby() and .transform() to fill missing data appropriately for each group.
Your job is to fill in missing ‘age’ values for passengers on the Titanic with the median age from their ‘gender’ and ‘pclass’. To do this, you’ll group by the ‘sex’ and ‘pclass’ columns and transform each group with a custom function to call .fillna() and impute the median value.
The DataFrame has been pre-loaded as titanic. Explore it in the IPython Shell by printing the output of titanic.tail(10). Notice in particular the NaNs in the ‘age’ column.
Instructions
- Group titanic by ‘sex’ and ‘pclass’. Save the result as by_sex_class.
- Write a function called impute_median() that fills missing values with the median of a series. This has been done for you.
- Call .transform() with impute_median on the ‘age’ column of by_sex_class.
- Print the output of titanic.tail(10). This has been done for you - hit ‘Submit Answer’ to see how the missing values have now been imputed.
1
2
| titanic = pd.read_csv(titanic_data)
titanic.head()
|
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest |
|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.00 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
|---|
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.92 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
|---|
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2.00 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
|---|
| 3 | 1 | 0 | Allison, Mr. Hudson Joshua Creighton | male | 30.00 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | 135.0 | Montreal, PQ / Chesterville, ON |
|---|
| 4 | 1 | 0 | Allison, Mrs. Hudson J C (Bessie Waldo Daniels) | female | 25.00 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
|---|
1
2
3
4
5
6
7
8
9
10
| # Create a groupby object: by_sex_class
by_sex_class = titanic.groupby(['sex', 'pclass'])
# Write a function that imputes median
def impute_median(series):
return series.fillna(series.median())
# Impute age and assign to titanic['age']
titanic.age = by_sex_class['age'].transform(impute_median)
titanic.tail(10)
|
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest |
|---|
| 1299 | 3 | 0 | Yasbeck, Mr. Antoni | male | 27.0 | 1 | 0 | 2659 | 14.4542 | NaN | C | C | NaN | NaN |
|---|
| 1300 | 3 | 1 | Yasbeck, Mrs. Antoni (Selini Alexander) | female | 15.0 | 1 | 0 | 2659 | 14.4542 | NaN | C | NaN | NaN | NaN |
|---|
| 1301 | 3 | 0 | Youseff, Mr. Gerious | male | 45.5 | 0 | 0 | 2628 | 7.2250 | NaN | C | NaN | 312.0 | NaN |
|---|
| 1302 | 3 | 0 | Yousif, Mr. Wazli | male | 25.0 | 0 | 0 | 2647 | 7.2250 | NaN | C | NaN | NaN | NaN |
|---|
| 1303 | 3 | 0 | Yousseff, Mr. Gerious | male | 25.0 | 0 | 0 | 2627 | 14.4583 | NaN | C | NaN | NaN | NaN |
|---|
| 1304 | 3 | 0 | Zabour, Miss. Hileni | female | 14.5 | 1 | 0 | 2665 | 14.4542 | NaN | C | NaN | 328.0 | NaN |
|---|
| 1305 | 3 | 0 | Zabour, Miss. Thamine | female | 22.0 | 1 | 0 | 2665 | 14.4542 | NaN | C | NaN | NaN | NaN |
|---|
| 1306 | 3 | 0 | Zakarian, Mr. Mapriededer | male | 26.5 | 0 | 0 | 2656 | 7.2250 | NaN | C | NaN | 304.0 | NaN |
|---|
| 1307 | 3 | 0 | Zakarian, Mr. Ortin | male | 27.0 | 0 | 0 | 2670 | 7.2250 | NaN | C | NaN | NaN | NaN |
|---|
| 1308 | 3 | 0 | Zimmerman, Mr. Leo | male | 29.0 | 0 | 0 | 315082 | 7.8750 | NaN | S | NaN | NaN | NaN |
|---|
The .apply() method when used on a groupby object performs an arbitrary function on each of the groups. These functions can be aggregations, transformations or more complex workflows. The .apply() method will then combine the results in an intelligent way.
In this exercise, you’re going to analyze economic disparity within regions of the world using the Gapminder data set for 2010. To do this you’ll define a function to compute the aggregate spread of per capita GDP in each region and the individual country’s z-score of the regional per capita GDP. You’ll then select three countries - United States, Great Britain and China - to see a summary of the regional GDP and that country’s z-score against the regional mean.
The 2010 Gapminder DataFrame is provided for you as gapminder_2010. Pandas has been imported as pd.
The following function has been defined for your use:
1
2
3
4
5
6
7
| def disparity(gr):
# Compute the spread of gr['gdp']: s
s = gr['gdp'].max() - gr['gdp'].min()
# Compute the z-score of gr['gdp'] as (gr['gdp']-gr['gdp'].mean())/gr['gdp'].std(): z
z = (gr['gdp'] - gr['gdp'].mean())/gr['gdp'].std()
# Return a DataFrame with the inputs {'z(gdp)':z, 'regional spread(gdp)':s}
return pd.DataFrame({'z(gdp)':z , 'regional spread(gdp)':s})
|
Instructions
- Group gapminder_2010 by ‘region’. Save the result as regional.
- Apply the provided disparity function on regional, and save the result as reg_disp.
- Use .loc[] to select [‘United States’,’United Kingdom’,’China’] from reg_disp and print the results.
1
2
3
4
5
6
7
| def disparity(gr):
# Compute the spread of gr['gdp']: s
s = gr['gdp'].max() - gr['gdp'].min()
# Compute the z-score of gr['gdp'] as (gr['gdp']-gr['gdp'].mean())/gr['gdp'].std(): z
z = (gr['gdp'] - gr['gdp'].mean())/gr['gdp'].std()
# Return a DataFrame with the inputs {'z(gdp)':z, 'regional spread(gdp)':s}
return pd.DataFrame({'z(gdp)':z , 'regional spread(gdp)':s})
|
| fertility | life | population | child_mortality | gdp | region |
|---|
| Country | | | | | | |
|---|
| Afghanistan | 5.659 | 59.612 | 31411743.0 | 105.0 | 1637.0 | South Asia |
|---|
| Albania | 1.741 | 76.780 | 3204284.0 | 16.6 | 9374.0 | Europe & Central Asia |
|---|
| Algeria | 2.817 | 70.615 | 35468208.0 | 27.4 | 12494.0 | Middle East & North Africa |
|---|
| Angola | 6.218 | 50.689 | 19081912.0 | 182.5 | 7047.0 | Sub-Saharan Africa |
|---|
| Antigua and Barbuda | 2.130 | 75.437 | 88710.0 | 9.9 | 20567.0 | America |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
| # Group gapminder_2010 by 'region': regional
regional = gapminder_2010.groupby('region')
# Apply the disparity function on regional: reg_disp
reg_disp = regional.apply(disparity)
# Get the 'Country' level values from the DataFrame's index
countries = reg_disp.index.get_level_values('Country')
# Now you can use 'regions' in your operations
reg_disp = reg_disp.loc[countries.isin(['United States', 'United Kingdom', 'China'])]
reg_disp
|
| | z(gdp) | regional spread(gdp) |
|---|
| region | Country | | |
|---|
| America | United States | 3.013374 | 47855.0 |
|---|
| East Asia & Pacific | China | -0.432756 | 96993.0 |
|---|
| Europe & Central Asia | United Kingdom | 0.572873 | 89037.0 |
|---|
Groupby and filterning
The automobile dataset
| mpg | cyl | displ | hp | weight | accel | yr | origin | name |
|---|
| 0 | 18.0 | 8 | 307.0 | 130 | 3504 | 12.0 | 70 | US | chevrolet chevelle malibu |
|---|
| 1 | 15.0 | 8 | 350.0 | 165 | 3693 | 11.5 | 70 | US | buick skylark 320 |
|---|
| 2 | 18.0 | 8 | 318.0 | 150 | 3436 | 11.0 | 70 | US | plymouth satellite |
|---|
| 3 | 16.0 | 8 | 304.0 | 150 | 3433 | 12.0 | 70 | US | amc rebel sst |
|---|
| 4 | 17.0 | 8 | 302.0 | 140 | 3449 | 10.5 | 70 | US | ford torino |
|---|
Mean MPG by year
1
| auto.groupby('yr')['mpg'].mean()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| yr
70 17.689655
71 21.111111
72 18.714286
73 17.100000
74 22.769231
75 20.266667
76 21.573529
77 23.375000
78 24.061111
79 25.093103
80 33.803704
81 30.185714
82 32.000000
Name: mpg, dtype: float64
|
groupby object
1
2
| splitting = auto.groupby('yr')
type(splitting)
|
1
| pandas.core.groupby.generic.DataFrameGroupBy
|
1
| pandas.io.formats.printing.PrettyDict
|
1
| print(splitting.groups.keys())
|
1
| dict_keys([70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82])
|
groupby object: iteration
1
2
3
| for group_name, group in splitting:
avg = group['mpg'].mean()
print(group_name, avg)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| 70 17.689655172413794
71 21.11111111111111
72 18.714285714285715
73 17.1
74 22.76923076923077
75 20.266666666666666
76 21.573529411764707
77 23.375
78 24.061111111111114
79 25.09310344827585
80 33.803703703703704
81 30.18571428571429
82 32.0
|
groupby object: iteration and filtering
1
2
3
| for group_name, group in splitting:
avg = group.loc[group['name'].str.contains('chevrolet'), 'mpg'].mean()
print(group_name, avg)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| 70 15.666666666666666
71 20.25
72 15.333333333333334
73 14.833333333333334
74 18.666666666666668
75 17.666666666666668
76 23.25
77 20.25
78 23.233333333333334
79 21.666666666666668
80 30.05
81 23.5
82 29.0
|
groupby object: comprehension
1
2
| chevy_means = {year:group.loc[group['name'].str.contains('chevrolet'),'mpg'].mean() for year,group in splitting}
pd.Series(chevy_means)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| 70 15.666667
71 20.250000
72 15.333333
73 14.833333
74 18.666667
75 17.666667
76 23.250000
77 20.250000
78 23.233333
79 21.666667
80 30.050000
81 23.500000
82 29.000000
dtype: float64
|
Boolean groupby
1
2
| chevy = auto['name'].str.contains('chevrolet')
auto.groupby(['yr', chevy])['mpg'].mean()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| yr name
70 False 17.923077
True 15.666667
71 False 21.260870
True 20.250000
72 False 19.120000
True 15.333333
73 False 17.500000
True 14.833333
74 False 23.304348
True 18.666667
75 False 20.555556
True 17.666667
76 False 21.350000
True 23.250000
77 False 23.895833
True 20.250000
78 False 24.136364
True 23.233333
79 False 25.488462
True 21.666667
80 False 34.104000
True 30.050000
81 False 30.433333
True 23.500000
82 False 32.461538
True 29.000000
Name: mpg, dtype: float64
|
Exercises
Grouping and filtering with .apply()
By using .apply(), you can write functions that filter rows within groups. The .apply() method will handle the iteration over individual groups and then re-combine them back into a Series or DataFrame.
In this exercise you’ll take the Titanic data set and analyze survival rates from the ‘C’ deck, which contained the most passengers. To do this you’ll group the dataset by ‘sex’ and then use the .apply() method on a provided user defined function which calculates the mean survival rates on the ‘C’ deck:
1
2
3
| def c_deck_survival(gr):
c_passengers = gr['cabin'].str.startswith('C').fillna(False)
return gr.loc[c_passengers, 'survived'].mean()
|
The DataFrame has been pre-loaded as titanic.
Instructions
- Group titanic by ‘sex’. Save the result as by_sex.
- Apply the provided c_deck_survival function on the by_sex DataFrame. Save the result as c_surv_by_sex.
- Print c_surv_by_sex.
1
2
| titanic = pd.read_csv(titanic_data)
titanic.head(3)
|
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest |
|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.00 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
|---|
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.92 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
|---|
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2.00 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
|---|
1
2
3
| def c_deck_survival(gr):
c_passengers = gr['cabin'].str.startswith('C').fillna(False)
return gr.loc[c_passengers, 'survived'].mean()
|
1
2
3
4
5
6
| # Create a groupby object using titanic over the 'sex' column: by_sex
by_sex = titanic.groupby('sex')
# Call by_sex.apply with the function c_deck_survival
c_surv_by_sex = by_sex.apply(c_deck_survival)
c_surv_by_sex.head()
|
1
2
3
4
| sex
female 0.913043
male 0.312500
dtype: float64
|
Grouping and filtering with .filter()
You can use groupby with the .filter() method to remove whole groups of rows from a DataFrame based on a boolean condition.
In this exercise, you’ll take the February sales data and remove entries from companies that purchased less than or equal to 35 Units in the whole month.
First, you’ll identify how many units each company bought for verification. Next you’ll use the .filter() method after grouping by ‘Company’ to remove all rows belonging to companies whose sum over the ‘Units’ column was less than or equal to 35. Finally, verify that the three companies whose total Units purchased were less than or equal to 35 have been filtered out from the DataFrame.
Instructions
- Group sales by ‘Company’. Save the result as by_company.
- Compute and print the sum of the ‘Units’ column of by_company.
- Call .filter() on by_company with lambda g:g[‘Units’].sum() > 35 as input and print the result.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| sales_values = np.array([['2015-02-02 08:30:00', 'Hooli', 'Software', 3],
['2015-02-02 21:00:00', 'Mediacore', 'Hardware', 9],
['2015-02-03 14:00:00', 'Initech', 'Software', 13],
['2015-02-04 15:30:00', 'Streeplex', 'Software', 13],
['2015-02-04 22:00:00', 'Acme Coporation', 'Hardware', 14],
['2015-02-05 02:00:00', 'Acme Coporation', 'Software', 19],
['2015-02-05 22:00:00', 'Hooli', 'Service', 10],
['2015-02-07 23:00:00', 'Acme Coporation', 'Hardware', 1],
['2015-02-09 09:00:00', 'Streeplex', 'Service', 19],
['2015-02-09 13:00:00', 'Mediacore', 'Software', 7],
['2015-02-11 20:00:00', 'Initech', 'Software', 7],
['2015-02-11 23:00:00', 'Hooli', 'Software', 4],
['2015-02-16 12:00:00', 'Hooli', 'Software', 10],
['2015-02-19 11:00:00', 'Mediacore', 'Hardware', 16],
['2015-02-19 16:00:00', 'Mediacore', 'Service', 10],
['2015-02-21 05:00:00', 'Mediacore', 'Software', 3],
['2015-02-21 20:30:00', 'Hooli', 'Hardware', 3],
['2015-02-25 00:30:00', 'Initech', 'Service', 10],
['2015-02-26 09:00:00', 'Streeplex', 'Service', 4]])
sales_cols = ['Date', 'Company', 'Product', 'Units']
|
1
2
3
4
5
| sales = pd.DataFrame(sales_values, columns=sales_cols)
sales['Date'] = pd.to_datetime(sales['Date'])
sales.set_index('Date', inplace=True)
sales['Units'] = sales['Units'].astype('int64')
sales.head()
|
| Company | Product | Units |
|---|
| Date | | | |
|---|
| 2015-02-02 08:30:00 | Hooli | Software | 3 |
|---|
| 2015-02-02 21:00:00 | Mediacore | Hardware | 9 |
|---|
| 2015-02-03 14:00:00 | Initech | Software | 13 |
|---|
| 2015-02-04 15:30:00 | Streeplex | Software | 13 |
|---|
| 2015-02-04 22:00:00 | Acme Coporation | Hardware | 14 |
|---|
1
2
3
4
5
6
| # Group sales by 'Company': by_company
by_company = sales.groupby('Company')
# Compute the sum of the 'Units' of by_company: by_com_sum
by_com_sum = by_company['Units'].sum()
by_com_sum
|
1
2
3
4
5
6
7
| Company
Acme Coporation 34
Hooli 30
Initech 30
Mediacore 45
Streeplex 36
Name: Units, dtype: int64
|
1
2
3
| # Filter 'Units' where the sum is > 35: by_com_filt
by_com_filt = by_company.filter(lambda g: g['Units'].sum() > 35)
by_com_filt
|
| Company | Product | Units |
|---|
| Date | | | |
|---|
| 2015-02-02 21:00:00 | Mediacore | Hardware | 9 |
|---|
| 2015-02-04 15:30:00 | Streeplex | Software | 13 |
|---|
| 2015-02-09 09:00:00 | Streeplex | Service | 19 |
|---|
| 2015-02-09 13:00:00 | Mediacore | Software | 7 |
|---|
| 2015-02-19 11:00:00 | Mediacore | Hardware | 16 |
|---|
| 2015-02-19 16:00:00 | Mediacore | Service | 10 |
|---|
| 2015-02-21 05:00:00 | Mediacore | Software | 3 |
|---|
| 2015-02-26 09:00:00 | Streeplex | Service | 4 |
|---|
Filtering and grouping with .map()
You have seen how to group by a column, or by multiple columns. Sometimes, you may instead want to group by a function/transformation of a column. The key here is that the Series is indexed the same way as the DataFrame. You can also mix and match column grouping with Series grouping.
In this exercise your job is to investigate survival rates of passengers on the Titanic by ‘age’ and ‘pclass’. In particular, the goal is to find out what fraction of children under 10 survived in each ‘pclass’. You’ll do this by first creating a boolean array where True is passengers under 10 years old and False is passengers over 10. You’ll use .map() to change these values to strings.
Finally, you’ll group by the under 10 series and the ‘pclass’ column and aggregate the ‘survived’ column. The ‘survived’ column has the value 1 if the passenger survived and 0 otherwise. The mean of the ‘survived’ column is the fraction of passengers who lived.
The DataFrame has been pre-loaded for you as titanic.
Instructions
- Create a Boolean Series of titanic[‘age’] < 10 and call .map with {True:’under 10’, False:’over 10’}.
- Group titanic by the under10 Series and then compute and print the mean of the ‘survived’ column.
- Group titanic by the under10 Series as well as the ‘pclass’ column and then compute and print the mean of the ‘survived’ column.
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest |
|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.00 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
|---|
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.92 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
|---|
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2.00 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
|---|
1
2
3
| # Create the Boolean Series: under10
under10 = (titanic['age'] < 10).map({True:'under 10', False:'over 10'})
under10.head()
|
1
2
3
4
5
6
| 0 over 10
1 under 10
2 under 10
3 over 10
4 over 10
Name: age, dtype: object
|
1
2
3
| # Group by under10 and compute the survival rate
survived_mean_1 = titanic.groupby(under10)['survived'].mean()
survived_mean_1
|
1
2
3
4
| age
over 10 0.366748
under 10 0.609756
Name: survived, dtype: float64
|
1
2
3
| # Group by under10 and pclass and compute the survival rate
survived_mean_2 = titanic.groupby([under10, 'pclass'])['survived'].mean()
survived_mean_2
|
1
2
3
4
5
6
7
8
| age pclass
over 10 1 0.617555
2 0.380392
3 0.238897
under 10 1 0.750000
2 1.000000
3 0.446429
Name: survived, dtype: float64
|
Bringing it all together
Here, you will bring together everything you have learned in this course while working with data recorded from the Summer Olympic games that goes as far back as 1896! This is a rich dataset that will allow you to fully apply the data manipulation techniques you have learned. You will pivot, unstack, group, slice, and reshape your data as you explore this dataset and uncover some truly fascinating insights. Enjoy!
Case Study - Summer Olympics
Olympic medals dataset
1
2
| medals = pd.read_csv(medals_data)
medals.head()
|
| City | Edition | Sport | Discipline | Athlete | NOC | Gender | Event | Event_gender | Medal |
|---|
| 0 | Athens | 1896 | Aquatics | Swimming | HAJOS, Alfred | HUN | Men | 100m freestyle | M | Gold |
|---|
| 1 | Athens | 1896 | Aquatics | Swimming | HERSCHMANN, Otto | AUT | Men | 100m freestyle | M | Silver |
|---|
| 2 | Athens | 1896 | Aquatics | Swimming | DRIVAS, Dimitrios | GRE | Men | 100m freestyle for sailors | M | Bronze |
|---|
| 3 | Athens | 1896 | Aquatics | Swimming | MALOKINIS, Ioannis | GRE | Men | 100m freestyle for sailors | M | Gold |
|---|
| 4 | Athens | 1896 | Aquatics | Swimming | CHASAPIS, Spiridon | GRE | Men | 100m freestyle for sailors | M | Silver |
|---|
Reminder: indexing & pivoting
- Filtering and indexing
- One-level indexing
- Multi-level indexing
- Reshaping DataFrames with pivot()
- pivot_table()
Reminder: groupby
- Useful DataFrame methods
- Aggregations, transformations, filtering
Case Study Explorations
Grouping and aggregating
The Olympic medal data for the following exercises comes from The Guardian. It comprises records of all events held at the Olympic games between 1896 and 2012.
Suppose you have loaded the data into a DataFrame medals. You now want to find the total number of medals awarded to the USA per edition. To do this, filter the ‘USA’ rows and use the groupby() function to put the ‘Edition’ column on the index:
1
| USA_edition_grouped = medals.loc[medals.NOC == 'USA'].groupby('Edition')
|
Given the goal of finding the total number of USA medals awarded per edition, what column should you select and which aggregation method should you use?
Instructions
Possible Answers
1
2
3
4
| USA_edition_grouped['City'].mean()
USA_edition_grouped['Athlete'].sum()
USA_edition_grouped['Medal'].count()
USA_edition_grouped['Gender'].first()
|
1
| USA_edition_grouped = medals.loc[medals.NOC == 'USA'].groupby('Edition')
|
1
| USA_edition_grouped['Medal'].count().head()
|
1
2
3
4
5
6
7
| Edition
1896 20
1900 55
1904 394
1908 63
1912 101
Name: Medal, dtype: int64
|
Using .value_counts() for ranking
For this exercise, you will use the pandas Series method .value_counts() to determine the top 15 countries ranked by total number of medals.
Notice that .value_counts() sorts by values by default. The result is returned as a Series of counts indexed by unique entries from the original Series with values (counts) ranked in descending order.
The DataFrame has been pre-loaded for you as medals.
Instructions
- Extract the ‘NOC’ column from the DataFrame medals and assign the result to country_names. Notice that this Series has repeated entries for every medal (of any type) a country has won in any Edition of the Olympics.
- Create a Series medal_counts by applying .value_counts() to the Series country_names.
- Print the top 15 countries ranked by total number of medals won. This has been done for you, so hit ‘Submit Answer’ to see the result.
1
2
3
| # Select the 'NOC' column of medals: country_names
country_names = medals['NOC']
country_names.head()
|
1
2
3
4
5
6
| 0 HUN
1 AUT
2 GRE
3 GRE
4 GRE
Name: NOC, dtype: object
|
1
2
3
4
5
| # Count the number of medals won by each country: medal_counts
medal_counts = country_names.value_counts()
# Print top 15 countries ranked by medals
print(medal_counts.head(15))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| NOC
USA 4335
URS 2049
GBR 1594
FRA 1314
ITA 1228
GER 1211
AUS 1075
HUN 1053
SWE 1021
GDR 825
NED 782
JPN 704
CHN 679
RUS 638
ROU 624
Name: count, dtype: int64
|
Using .pivot_table() to count medals by type
Rather than ranking countries by total medals won and showing that list, you may want to see a bit more detail. You can use a pivot table to compute how many separate bronze, silver and gold medals each country won. That pivot table can then be used to repeat the previous computation to rank by total medals won.
In this exercise, you will use .pivot_table() first to aggregate the total medals by type. Then, you can use .sum() along the columns of the pivot table to produce a new column. When the modified pivot table is sorted by the total medals column, you can display the results from the last exercise with a bit more detail.
Instructions
- Construct a pivot table counted from the DataFrame medals aggregating by count. Use ‘NOC’ as the index, ‘Athlete’ for the values, and ‘Medal’ for the columns.
- Modify the DataFrame counted by adding a column counted[‘totals’]. The new column ‘totals’ should contain the result of taking the sum along the columns (i.e., use .sum(axis=’columns’)).
- Overwrite the DataFrame counted by sorting it with the .sort_values() method. Specify the keyword argument ascending=False.
- Print the first 15 rows of counted using .head(15). This has been done for you, so hit ‘Submit Answer’ to see the result.
1
2
3
4
5
6
| # Construct the pivot table: counted
counted = medals.pivot_table(index='NOC',
columns='Medal',
values='Athlete',
aggfunc='count')
counted.head()
|
| Medal | Bronze | Gold | Silver |
|---|
| NOC | | | |
|---|
| AFG | 1.0 | NaN | NaN |
|---|
| AHO | NaN | NaN | 1.0 |
|---|
| ALG | 8.0 | 4.0 | 2.0 |
|---|
| ANZ | 5.0 | 20.0 | 4.0 |
|---|
| ARG | 88.0 | 68.0 | 83.0 |
|---|
1
2
3
| # Create the new column: counted['totals']
counted['totals'] = counted.sum(axis='columns')
counted.head()
|
| Medal | Bronze | Gold | Silver | totals |
|---|
| NOC | | | | |
|---|
| AFG | 1.0 | NaN | NaN | 1.0 |
|---|
| AHO | NaN | NaN | 1.0 | 1.0 |
|---|
| ALG | 8.0 | 4.0 | 2.0 | 14.0 |
|---|
| ANZ | 5.0 | 20.0 | 4.0 | 29.0 |
|---|
| ARG | 88.0 | 68.0 | 83.0 | 239.0 |
|---|
1
2
3
| # Sort counted by the 'totals' column
counted = counted.sort_values('totals', ascending=False)
counted.head()
|
| Medal | Bronze | Gold | Silver | totals |
|---|
| NOC | | | | |
|---|
| USA | 1052.0 | 2088.0 | 1195.0 | 4335.0 |
|---|
| URS | 584.0 | 838.0 | 627.0 | 2049.0 |
|---|
| GBR | 505.0 | 498.0 | 591.0 | 1594.0 |
|---|
| FRA | 475.0 | 378.0 | 461.0 | 1314.0 |
|---|
| ITA | 374.0 | 460.0 | 394.0 | 1228.0 |
|---|
Understanding the column labels
‘Gender’ and ‘Event_gender’
1
| medals.loc[145:154, ['NOC', 'Gender', 'Event', 'Event_gender', 'Medal']]
|
| NOC | Gender | Event | Event_gender | Medal |
|---|
| 145 | GRE | Men | heavyweight - two hand lift | M | Bronze |
|---|
| 146 | DEN | Men | heavyweight - two hand lift | M | Gold |
|---|
| 147 | GBR | Men | heavyweight - two hand lift | M | Silver |
|---|
| 148 | GRE | Men | open event | M | Bronze |
|---|
| 149 | GER | Men | open event | M | Gold |
|---|
| 150 | GRE | Men | open event | M | Silver |
|---|
| 151 | HUN | Men | 1500m freestyle | M | Bronze |
|---|
| 152 | GBR | Men | 1500m freestyle | M | Gold |
|---|
| 153 | AUT | Men | 1500m freestyle | M | Silver |
|---|
| 154 | NED | Men | 200m backstroke | M | Bronze |
|---|
Reminder: slicing & filtering
- Indexing and slicing
- .loc[] and .iloc[] accessors
- Filtering
- Selecting by Boolean Series
- Filtering null/non-null and zero/non-zero values
Reminder: Handling categorical data
- Useful DataFrame methods for handling categorical data:
- value_counts()
- unique()
- groupby()
- groupby() aggregations:
Case Study Explorations
Applying .drop_duplicates()
What could be the difference between the ‘Event_gender’ and ‘Gender’ columns? You should be able to evaluate your guess by looking at the unique values of the pairs (Event_gender, Gender) in the data. In particular, you should not see something like (Event_gender=’M’, Gender=’Women’). However, you will see that, strangely enough, there is an observation with (Event_gender=’W’, Gender=’Men’).
The duplicates can be dropped using the .drop_duplicates() method, leaving behind the unique observations. The DataFrame has been loaded as medals.
Instructions
- Select the columns ‘Event_gender’ and ‘Gender’.
- Create a dataframe ev_gen_uniques containing the unique pairs contained in ev_gen.
- Print ev_gen_uniques. This has been done for you, so hit ‘Submit Answer’ to see the result.
1
2
| medals = pd.read_csv(medals_data)
medals.head()
|
| City | Edition | Sport | Discipline | Athlete | NOC | Gender | Event | Event_gender | Medal |
|---|
| 0 | Athens | 1896 | Aquatics | Swimming | HAJOS, Alfred | HUN | Men | 100m freestyle | M | Gold |
|---|
| 1 | Athens | 1896 | Aquatics | Swimming | HERSCHMANN, Otto | AUT | Men | 100m freestyle | M | Silver |
|---|
| 2 | Athens | 1896 | Aquatics | Swimming | DRIVAS, Dimitrios | GRE | Men | 100m freestyle for sailors | M | Bronze |
|---|
| 3 | Athens | 1896 | Aquatics | Swimming | MALOKINIS, Ioannis | GRE | Men | 100m freestyle for sailors | M | Gold |
|---|
| 4 | Athens | 1896 | Aquatics | Swimming | CHASAPIS, Spiridon | GRE | Men | 100m freestyle for sailors | M | Silver |
|---|
1
2
3
| # Select columns: ev_gen
ev_gen = medals[['Event_gender', 'Gender']]
ev_gen.head()
|
| Event_gender | Gender |
|---|
| 0 | M | Men |
|---|
| 1 | M | Men |
|---|
| 2 | M | Men |
|---|
| 3 | M | Men |
|---|
| 4 | M | Men |
|---|
1
2
3
| # Drop duplicate pairs: ev_gen_uniques
ev_gen_uniques = ev_gen.drop_duplicates()
ev_gen_uniques
|
| Event_gender | Gender |
|---|
| 0 | M | Men |
|---|
| 348 | X | Men |
|---|
| 416 | W | Women |
|---|
| 639 | X | Women |
|---|
| 23675 | W | Men |
|---|
Finding possible errors with .groupby()
You will now use .groupby() to continue your exploration. Your job is to group by ‘Event_gender’ and ‘Gender’ and count the rows.
You will see that there is only one suspicious row: This is likely a data error.
The DataFrame is available to you as medals.
Instructions
- Group medals by ‘Event_gender’ and ‘Gender’.
- Create a medal_count_by_gender DataFrame with a group count using the .count() method.
- Print medal_count_by_gender. This has been done for you, so hit ‘Submit Answer’ to view the result.
1
2
3
4
5
6
| # Group medals by the two columns: medals_by_gender
medals_by_gender = medals.groupby(['Event_gender', 'Gender'])
# Create a DataFrame with a group count: medal_count_by_gender
medal_count_by_gender = medals_by_gender.count()
medal_count_by_gender
|
| | City | Edition | Sport | Discipline | Athlete | NOC | Event | Medal |
|---|
| Event_gender | Gender | | | | | | | | |
|---|
| M | Men | 20067 | 20067 | 20067 | 20067 | 20067 | 20067 | 20067 | 20067 |
|---|
| W | Men | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|
| Women | 7277 | 7277 | 7277 | 7277 | 7277 | 7277 | 7277 | 7277 |
|---|
| X | Men | 1653 | 1653 | 1653 | 1653 | 1653 | 1653 | 1653 | 1653 |
|---|
| Women | 218 | 218 | 218 | 218 | 218 | 218 | 218 | 218 |
|---|
Locating suspicious data
You will now inspect the suspect record by locating the offending row.
You will see that, according to the data, Joyce Chepchumba was a man that won a medal in a women’s event. That is a data error as you can confirm with a web search.
Instructions
- Create a Boolean Series with a condition that captures the only row that has medals.Event_gender == ‘W’ and medals.Gender == ‘Men’. Be sure to use the & operator.
- Use the Boolean Series to create a DataFrame called suspect with the suspicious row.
- Print suspect. This has been done for you, so hit ‘Submit Answer’ to see the result.
1
2
3
4
5
6
| # Create the Boolean Series: sus
sus = (medals.Event_gender == 'W') & (medals.Gender == 'Men')
# Create a DataFrame with the suspicious row: suspect
suspect = medals[sus]
suspect
|
| City | Edition | Sport | Discipline | Athlete | NOC | Gender | Event | Event_gender | Medal |
|---|
| 23675 | Sydney | 2000 | Athletics | Athletics | CHEPCHUMBA, Joyce | KEN | Men | marathon | W | Bronze |
|---|
Constructing alternative country rankings
Counting distinct events
1
2
| sports = medals['Sport'].unique()
sports
|
1
2
3
4
5
6
7
8
9
| array(['Aquatics', 'Athletics', 'Cycling', 'Fencing', 'Gymnastics',
'Shooting', 'Tennis', 'Weightlifting', 'Wrestling', 'Archery',
'Basque Pelota', 'Cricket', 'Croquet', 'Equestrian', 'Football',
'Golf', 'Polo', 'Rowing', 'Rugby', 'Sailing', 'Tug of War',
'Boxing', 'Lacrosse', 'Roque', 'Hockey', 'Jeu de paume', 'Rackets',
'Skating', 'Water Motorsports', 'Modern Pentathlon', 'Ice Hockey',
'Basketball', 'Canoe / Kayak', 'Handball', 'Judo', 'Volleyball',
'Table Tennis', 'Badminton', 'Baseball', 'Softball', 'Taekwondo',
'Triathlon'], dtype=object)
|
Ranking of distinct events
- Top five countries that have won medals in the most sports
- Compare medal counts of USA and USSR from 1952 to 1988
Two new DataFrame methods
- idxmax(): Row or column label where maximum value is located
- idxmin(): Row or column label where minimum value is located
idxmax() Example
1
2
3
4
5
6
| weather = pd.DataFrame({'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',
'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'],
'Mean TemperatureF': [32.354839, 28.714286, 35.000000, 53.100000, 62.612903, 70.133333,
72.870968, 70.000000, 63.766667, 55.451613, 39.800000, 34.935484]})
weather.set_index('Month', inplace=True)
weather
|
| Mean TemperatureF |
|---|
| Month | |
|---|
| Jan | 32.354839 |
|---|
| Feb | 28.714286 |
|---|
| Mar | 35.000000 |
|---|
| Apr | 53.100000 |
|---|
| May | 62.612903 |
|---|
| Jun | 70.133333 |
|---|
| Jul | 72.870968 |
|---|
| Aug | 70.000000 |
|---|
| Sep | 63.766667 |
|---|
| Oct | 55.451613 |
|---|
| Nov | 39.800000 |
|---|
| Dec | 34.935484 |
|---|
Using idxmax()
1
| weather.idxmax() # Returns month of highest temperature
|
1
2
| Mean TemperatureF Jul
dtype: object
|
Using idxmax() along columns
1
| weather.T # Returns DataFrame with single row, 12 columns
|
| Month | Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec |
|---|
| Mean TemperatureF | 32.354839 | 28.714286 | 35.0 | 53.1 | 62.612903 | 70.133333 | 72.870968 | 70.0 | 63.766667 | 55.451613 | 39.8 | 34.935484 |
|---|
1
| weather.T.idxmax(axis='columns')
|
1
2
| Mean TemperatureF Jul
dtype: object
|
Using idxmin()
1
| weather.T.idxmin(axis='columns')
|
1
2
| Mean TemperatureF Feb
dtype: object
|
Case Study Explorations
Using .nunique() to rank by distinct sports
You may want to know which countries won medals in the most distinct sports. The .nunique() method is the principal aggregation here. Given a categorical Series S, S.nunique() returns the number of distinct categories.
Instructions
- Group medals by ‘NOC’.
- Compute the number of distinct sports in which each country won medals. To do this, select the ‘Sport’ column from country_grouped and apply .nunique().
- Sort Nsports in descending order with .sort_values() and ascending=False.
- Print the first 15 rows of Nsports. This has been done for you, so hit ‘Submit Answer’ to see the result.
1
2
3
4
5
6
7
8
9
10
11
| # Group medals by 'NOC': country_grouped
country_grouped = medals.groupby('NOC')
# Compute the number of distinct sports in which each country won medals: Nsports
Nsports = country_grouped['Sport'].nunique()
# Sort the values of Nsports in descending order
Nsports = Nsports.sort_values(ascending=False)
# Print the top 15 rows of Nsports
print(Nsports.head(15))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| NOC
USA 34
GBR 31
FRA 28
GER 26
CHN 24
CAN 22
AUS 22
ESP 22
SWE 21
ITA 21
URS 21
NED 20
RUS 20
JPN 20
TCH 19
Name: Sport, dtype: int64
|
The USSR is not in the top 5 in this category, while the USA continues to remain on top. What could be the cause of this? You’ll compare the medal counts of USA vs. USSR more closely in the next two exercises to find out.
Counting USA vs. USSR Cold War Olympic Sports
The Olympic competitions between 1952 and 1988 took place during the height of the Cold War between the United States of America (USA) & the Union of Soviet Socialist Republics (USSR). Your goal in this exercise is to aggregate the number of distinct sports in which the USA and the USSR won medals during the Cold War years.
The construction is mostly the same as in the preceding exercise. There is an additional filtering stage beforehand in which you reduce the original DataFrame medals by extracting data from the Cold War period that applies only to the US or to the USSR. The relevant country codes in the DataFrame, which has been pre-loaded as medals, are ‘USA’ & ‘URS’.
Instructions
- Using medals, create a Boolean Series called during_cold_war that is True when ‘Edition’ >= 1952 & <= 1988.
- Using medals, create a Boolean Series called is_usa_urs that is True when ‘NOC’ is either ‘USA’ or ‘URS’.
- Filter the medals DataFrame using during_cold_war and is_usa_urs to create a new DataFrame called cold_war_medals.
- Group cold_war_medals by ‘NOC’.
- Create a Series Nsports from country_grouped using indexing & chained methods:
- Extract the column ‘Sport’.
- Use .nunique() to get the number of unique elements in each group;
- Apply .sort_values(ascending=False) to rearrange the Series.
- Print the final Series Nsports. This has been done for you, so hit ‘Submit Answer’ to see the result!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # Extract all rows for which the 'Edition' is between 1952 & 1988: during_cold_war
during_cold_war = (1952 <= medals.Edition) & (medals.Edition <= 1988)
# Extract rows for which 'NOC' is either 'USA' or 'URS': is_usa_urs
is_usa_urs = medals.NOC.isin(['USA', 'URS'])
# Use during_cold_war and is_usa_urs to create the DataFrame: cold_war_medals
cold_war_medals = medals.loc[during_cold_war & is_usa_urs]
# Group cold_war_medals by 'NOC'
country_grouped = cold_war_medals.groupby('NOC')
# Create Nsports
Nsports = country_grouped['Sport'].nunique().sort_values(ascending=False)
Nsports
|
1
2
3
4
| NOC
URS 21
USA 20
Name: Sport, dtype: int64
|
As you can see, the USSR is actually higher than the US when you look only at the Olympic competitions between 1952 and 1988.
Counting USA vs. USSR Cold War Olympic Medals
For this exercise, you want to see which country, the USA or the USSR, won the most medals consistently over the Cold War period.
There are several steps involved in carrying out this computation.
- You’ll need a pivot table with years (‘Edition’) on the index and countries (‘NOC’) on the columns. The entries will be the total number of medals each country won that year. If the country won no medals in a given edition, expect a NaN in that entry of the pivot table.
- You’ll need to slice the Cold War period and subset the ‘USA’ and ‘URS’ columns.
- You’ll need to make a Series from this slice of the pivot table that tells which country won the most medals in that edition using .idxmax(axis=’columns’). If .max() returns the maximum value of Series or 1D array, .idxmax() returns the index of the maximizing element. The argument axis=columns or axis=1 is required because, by default, this aggregation would be done along columns for a DataFrame.
- The final Series contains either ‘USA’ or ‘URS’ according to which country won the most medals in each Olympic edition. You can use .value_counts() to count the number of occurrences of each.
Instructions
- Construct medals_won_by_country using medals.pivot_table().
- The index should be the years (‘Edition’) & the columns should be country (‘NOC’)
- The values should be ‘Athlete’ (which captures every medal regardless of kind) & the aggregation method should be ‘count’ (which captures the total number of medals won).
- Create cold_war_usa_urs_medals by slicing the pivot table medals_won_by_country. Your slice should contain the editions from years 1952:1988 and only the columns ‘USA’ & ‘URS’ from the pivot table.
- Create the Series most_medals by applying the .idxmax() method to cold_war_usa_urs_medals. Be sure to use axis=’columns’.
- Print the result of applying .value_counts() to most_medals. The result reported gives the number of times each of the USA or the USSR won more Olympic medals in total than the other between 1952 and 1988.
1
2
3
4
5
6
| # Create the pivot table: medals_won_by_country
medals_won_by_country = medals.pivot_table(index='Edition',
columns='NOC',
values='Athlete',
aggfunc='count')
medals_won_by_country.head()
|
| NOC | AFG | AHO | ALG | ANZ | ARG | ARM | AUS | AUT | AZE | BAH | BAR | BDI | BEL | BER | BLR | BOH | BRA | BUL | BWI | CAN | CHI | CHN | CIV | CMR | COL | ... | SWE | SYR | TAN | TCH | TGA | THA | TJK | TOG | TPE | TRI | TUN | TUR | UAE | UGA | UKR | URS | URU | USA | UZB | VEN | VIE | YUG | ZAM | ZIM | ZZX |
|---|
| Edition | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
|---|
| 1896 | NaN | NaN | NaN | NaN | NaN | NaN | 2.0 | 5.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 20.0 | NaN | NaN | NaN | NaN | NaN | NaN | 6.0 |
|---|
| 1900 | NaN | NaN | NaN | NaN | NaN | NaN | 5.0 | 6.0 | NaN | NaN | NaN | NaN | 39.0 | NaN | NaN | 2.0 | NaN | NaN | NaN | 2.0 | NaN | NaN | NaN | NaN | NaN | ... | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 55.0 | NaN | NaN | NaN | NaN | NaN | NaN | 34.0 |
|---|
| 1904 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 35.0 | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 394.0 | NaN | NaN | NaN | NaN | NaN | NaN | 8.0 |
|---|
| 1908 | NaN | NaN | NaN | 19.0 | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | 31.0 | NaN | NaN | 5.0 | NaN | NaN | NaN | 51.0 | NaN | NaN | NaN | NaN | NaN | ... | 98.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 63.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
|---|
| 1912 | NaN | NaN | NaN | 10.0 | NaN | NaN | NaN | 14.0 | NaN | NaN | NaN | NaN | 19.0 | NaN | NaN | NaN | NaN | NaN | NaN | 8.0 | NaN | NaN | NaN | NaN | NaN | ... | 173.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 101.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
|---|
5 rows × 138 columns
1
2
3
4
5
6
7
8
| # Slice medals_won_by_country: cold_war_usa_urs_medals
cold_war_usa_urs_medals = medals_won_by_country.loc[1952:1988 , ['USA','URS']]
# Create most_medals
most_medals = cold_war_usa_urs_medals.idxmax(axis='columns')
# Print most_medals.value_counts()
most_medals.value_counts()
|
1
2
3
| URS 8
USA 2
Name: count, dtype: int64
|
Reshaping DataFrames for visualization
Data
1
| medals = pd.read_csv(medals_data)
|
Reminder: plotting DataFrames
1
2
| all_medals = medals.groupby('Edition')['Athlete'].count()
all_medals.head(6) # Series for all medals, all years
|
1
2
3
4
5
6
7
8
| Edition
1896 151
1900 512
1904 470
1908 804
1912 885
1920 1298
Name: Athlete, dtype: int64
|
Plotting DataFrames
1
2
| all_medals.plot(kind='line', marker='.')
plt.show()
|
Grouping the data
1
2
3
| france = medals.NOC == 'FRA' # Boolean Series for France
france_grps = medals[france].groupby(['Edition', 'Medal'])
france_grps['Athlete'].count().head(10)
|
1
2
3
4
5
6
7
8
9
10
11
12
| Edition Medal
1896 Bronze 2
Gold 5
Silver 4
1900 Bronze 53
Gold 46
Silver 86
1908 Bronze 21
Gold 9
Silver 5
1912 Bronze 5
Name: Athlete, dtype: int64
|
Reshaping the data
1
2
| france_medals = france_grps['Athlete'].count().unstack()
france_medals.head(12) # Single level index
|
| Medal | Bronze | Gold | Silver |
|---|
| Edition | | | |
|---|
| 1896 | 2.0 | 5.0 | 4.0 |
|---|
| 1900 | 53.0 | 46.0 | 86.0 |
|---|
| 1908 | 21.0 | 9.0 | 5.0 |
|---|
| 1912 | 5.0 | 10.0 | 10.0 |
|---|
| 1920 | 55.0 | 13.0 | 73.0 |
|---|
| 1924 | 20.0 | 39.0 | 63.0 |
|---|
| 1928 | 13.0 | 7.0 | 16.0 |
|---|
| 1932 | 6.0 | 23.0 | 8.0 |
|---|
| 1936 | 18.0 | 12.0 | 13.0 |
|---|
| 1948 | 21.0 | 25.0 | 22.0 |
|---|
| 1952 | 16.0 | 14.0 | 9.0 |
|---|
| 1956 | 13.0 | 6.0 | 13.0 |
|---|
Plotting the result
1
2
| france_medals.plot(kind='line', marker='.')
plt.show()
|
Case Study Explorations
Visualizing USA Medal Counts by Edition: Line Plot
Your job in this exercise is to visualize the medal counts by ‘Edition’ for the USA. The DataFrame has been pre-loaded for you as medals.
Instructions
- Create a DataFrame usa with data only for the USA.
- Group usa such that [‘Edition’, ‘Medal’] is the index. Aggregate the count over ‘Athlete’.
- Use .unstack() with level=’Medal’ to reshape the DataFrame usa_medals_by_year.
- Construct a line plot from the final DataFrame usa_medals_by_year. This has been done for you, so hit ‘Submit Answer’ to see the plot!
| City | Edition | Sport | Discipline | Athlete | NOC | Gender | Event | Event_gender | Medal |
|---|
| 0 | Athens | 1896 | Aquatics | Swimming | HAJOS, Alfred | HUN | Men | 100m freestyle | M | Gold |
|---|
| 1 | Athens | 1896 | Aquatics | Swimming | HERSCHMANN, Otto | AUT | Men | 100m freestyle | M | Silver |
|---|
| 2 | Athens | 1896 | Aquatics | Swimming | DRIVAS, Dimitrios | GRE | Men | 100m freestyle for sailors | M | Bronze |
|---|
| 3 | Athens | 1896 | Aquatics | Swimming | MALOKINIS, Ioannis | GRE | Men | 100m freestyle for sailors | M | Gold |
|---|
| 4 | Athens | 1896 | Aquatics | Swimming | CHASAPIS, Spiridon | GRE | Men | 100m freestyle for sailors | M | Silver |
|---|
1
2
3
| # Create the DataFrame: usa
usa = medals[medals.NOC == 'USA']
usa.head()
|
| City | Edition | Sport | Discipline | Athlete | NOC | Gender | Event | Event_gender | Medal |
|---|
| 11 | Athens | 1896 | Athletics | Athletics | LANE, Francis | USA | Men | 100m | M | Bronze |
|---|
| 13 | Athens | 1896 | Athletics | Athletics | BURKE, Thomas | USA | Men | 100m | M | Gold |
|---|
| 15 | Athens | 1896 | Athletics | Athletics | CURTIS, Thomas | USA | Men | 110m hurdles | M | Gold |
|---|
| 19 | Athens | 1896 | Athletics | Athletics | BLAKE, Arthur | USA | Men | 1500m | M | Silver |
|---|
| 21 | Athens | 1896 | Athletics | Athletics | BURKE, Thomas | USA | Men | 400m | M | Gold |
|---|
1
2
3
| # Group usa by ['Edition', 'Medal'] and aggregate over 'Athlete'
usa_medals_by_year = usa.groupby(['Edition', 'Medal'])['Athlete'].count()
usa_medals_by_year.head()
|
1
2
3
4
5
6
7
| Edition Medal
1896 Bronze 2
Gold 11
Silver 7
1900 Bronze 14
Gold 27
Name: Athlete, dtype: int64
|
1
2
3
4
5
6
| # Reshape usa_medals_by_year by unstacking
usa_medals_by_year = usa_medals_by_year.unstack(level='Medal')
# Plot the DataFrame usa_medals_by_year
usa_medals_by_year.plot()
plt.show()
|
Visualizing USA Medal Counts by Edition: Area Plot
As in the previous exercise, your job in this exercise is to visualize the medal counts by ‘Edition’ for the USA. This time, you will use an area plot to see the breakdown better. The usa DataFrame has been created and all reshaping from the previous exercise has been done. You need to write the plotting command.
Instructions
- Create an area plot of usa_medals_by_year. This can be done by using .plot.area().
1
2
3
4
5
6
7
8
9
10
11
12
| # Create the DataFrame: usa
usa = medals[medals.NOC == 'USA']
# Group usa by 'Edition', 'Medal', and 'Athlete'
usa_medals_by_year = usa.groupby(['Edition', 'Medal'])['Athlete'].count()
# Reshape usa_medals_by_year by unstacking
usa_medals_by_year = usa_medals_by_year.unstack(level='Medal')
# Create an area plot of usa_medals_by_year
usa_medals_by_year.plot.area()
plt.show()
|
1
| usa_medals_by_year.head()
|
| Medal | Bronze | Gold | Silver |
|---|
| Edition | | | |
|---|
| 1896 | 2 | 11 | 7 |
|---|
| 1900 | 14 | 27 | 14 |
|---|
| 1904 | 111 | 146 | 137 |
|---|
| 1908 | 15 | 34 | 14 |
|---|
| 1912 | 31 | 45 | 25 |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <class 'pandas.core.frame.DataFrame'>
RangeIndex: 29216 entries, 0 to 29215
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 City 29216 non-null object
1 Edition 29216 non-null int64
2 Sport 29216 non-null object
3 Discipline 29216 non-null object
4 Athlete 29216 non-null object
5 NOC 29216 non-null object
6 Gender 29216 non-null object
7 Event 29216 non-null object
8 Event_gender 29216 non-null object
9 Medal 29216 non-null object
dtypes: int64(1), object(9)
memory usage: 2.2+ MB
|
Visualizing USA Medal Counts by Edition: Area Plot with Ordered Medals
You may have noticed that the medals are ordered according to a lexicographic (dictionary) ordering: Bronze < Gold < Silver. However, you would prefer an ordering consistent with the Olympic rules: Bronze < Silver < Gold.
You can achieve this using Categorical types. In this final exercise, after redefining the ‘Medal’ column of the DataFrame medals, you will repeat the area plot from the previous exercise to see the new ordering.
Instructions
- Redefine the ‘Medal’ column of the DataFrame medals as an ordered categorical. To do this, use pd.Categorical() with three keyword arguments:
- values = medals.Medal.
- categories=[‘Bronze’, ‘Silver’, ‘Gold’].
- ordered=True.
- After this, you can verify that the type has changed using medals.info().
- Plot the final DataFrame usa_medals_by_year as an area plot. This has been done for you, so hit ‘Submit Answer’ to see how the plot has changed!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # Redefine 'Medal' as an ordered categorical
medals.Medal = pd.Categorical(values=medals.Medal,
categories=['Bronze', 'Silver', 'Gold'],
ordered=True)
# Create the DataFrame: usa
usa = medals[medals.NOC == 'USA']
# Group usa by 'Edition', 'Medal', and 'Athlete'
usa_medals_by_year = usa.groupby(['Edition', 'Medal'], observed=False)['Athlete'].count()
# Reshape usa_medals_by_year by unstacking
usa_medals_by_year = usa_medals_by_year.unstack(level='Medal')
# Create an area plot of usa_medals_by_year
usa_medals_by_year.plot.area()
plt.show()
|
| City | Edition | Sport | Discipline | Athlete | NOC | Gender | Event | Event_gender | Medal |
|---|
| 0 | Athens | 1896 | Aquatics | Swimming | HAJOS, Alfred | HUN | Men | 100m freestyle | M | Gold |
|---|
| 1 | Athens | 1896 | Aquatics | Swimming | HERSCHMANN, Otto | AUT | Men | 100m freestyle | M | Silver |
|---|
| 2 | Athens | 1896 | Aquatics | Swimming | DRIVAS, Dimitrios | GRE | Men | 100m freestyle for sailors | M | Bronze |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| <class 'pandas.core.frame.DataFrame'>
RangeIndex: 29216 entries, 0 to 29215
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 City 29216 non-null object
1 Edition 29216 non-null int64
2 Sport 29216 non-null object
3 Discipline 29216 non-null object
4 Athlete 29216 non-null object
5 NOC 29216 non-null object
6 Gender 29216 non-null object
7 Event 29216 non-null object
8 Event_gender 29216 non-null object
9 Medal 29216 non-null category
dtypes: category(1), int64(1), object(8)
memory usage: 2.0+ MB
|
1
| usa_medals_by_year.head()
|
| Medal | Bronze | Silver | Gold |
|---|
| Edition | | | |
|---|
| 1896 | 2 | 7 | 11 |
|---|
| 1900 | 14 | 14 | 27 |
|---|
| 1904 | 111 | 137 | 146 |
|---|
| 1908 | 15 | 14 | 34 |
|---|
| 1912 | 31 | 25 | 45 |
|---|
Final Thoughts
You can now…
- Transform, extract, and filter data from DataFrames
- Work with pandas indexes and hierarchical indexes
- Reshape and restructure your data
- Split your data into groups and categories
1
2
3
4
5
6
7
8
| import sys
# These are the usual ipython objects, including this one you are creating
ipython_vars = ['In', 'Out', 'exit', 'quit', 'get_ipython', 'ipython_vars']
# Get a sorted list of the objects and their sizes
sorted([(x, sys.getsizeof(globals().get(x))) for x in dir() if not x.startswith('_')
and x not in sys.modules and x not in ipython_vars], key=lambda x: x[1], reverse=True)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
| [('medals', 15496232),
('ev_gen', 3462642),
('usa', 2330626),
('cold_war_medals', 2130475),
('gapminder', 1901820),
('country_names', 1753124),
('gapminder_mask', 675797),
('titanic', 603665),
('life', 95093),
('under10', 84022),
('auto', 74338),
('unemployment', 51907),
('gapminder_2010', 36404),
('medals_won_by_country', 30016),
('during_cold_war', 29380),
('france', 29380),
('is_usa_urs', 29380),
('sus', 29380),
('regions', 28636),
('reg_disp', 22404),
('election', 20286),
('standardized', 16557),
('outliers', 13527),
('countries', 13325),
('right_columns', 12797),
('counted', 12728),
('middle_columns', 11725),
('results', 11725),
('left_columns', 11469),
('medal_counts', 9416),
('aggregated', 8783),
('df_celsius', 6004),
('group', 5974),
('sales_values', 5904),
('turnout_zscore', 4876),
('high_turnout', 4407),
('too_close', 4407),
('sales', 2812),
('skinny', 1728),
('NamespaceMagics', 1688),
('high_turnout_df', 1673),
('more_trials', 1220),
('by_com_filt', 1205),
('stocks', 1202),
('weather', 1148),
('p_counties', 966),
('p_counties_rev', 966),
('france_medals', 832),
('usa_medals_by_year', 832),
('medal_count_by_gender', 774),
('df2', 756),
('kv_pairs', 744),
('gm_outliers', 737),
('users', 720),
('most_medals', 712),
('trials', 692),
('visitors', 688),
('newusers', 675),
('users_idx', 675),
('ev_gen_uniques', 666),
('sorted_trials', 665),
('stacked', 665),
('swapped', 665),
('df_new', 660),
('chevy_means', 632),
('all_month2', 627),
('suspect', 623),
('CA_TX_month2', 601),
('by_com_sum', 574),
('enough_salt_sold', 570),
('shares', 565),
('chevy', 556),
('units_sum', 544),
('count_mult', 540),
('df', 536),
('three_counties', 463),
('survived_mean_2', 460),
('all_medals', 448),
('sports', 448),
('customers', 409),
('NY_month1', 347),
('signups_and_visitors', 322),
('visitors_by_city_weekday', 316),
('new_trials', 312),
('election_penn', 303),
('survived_mean_1', 285),
('Nsports', 276),
('cold_war_usa_urs_medals', 272),
('signups_and_visitors_total', 260),
('weather_data', 255),
('medals_data', 228),
('byweekday', 222),
('by_city_day', 216),
('bycity', 216),
('pivot', 216),
('gapminder_data', 213),
('trials_by_gender', 212),
('auto_mpg', 210),
('titanic_data', 210),
('sales2_data', 204),
('sales_data', 201),
('users_data', 201),
('count_by_weekday1', 200),
('count_by_weekday2', 200),
('aggregator', 184),
('red_vs_blue', 184),
('signups_pivot', 184),
('visitors_pivot', 184),
('c_surv_by_sex', 172),
('c_deck_survival', 152),
('data_range', 152),
('disparity', 152),
('dozens', 152),
('impute_median', 152),
('open', 152),
('spread', 152),
('to_celsius', 152),
('zscore', 152),
('zscore_def', 152),
('zscore_with_year_and_name', 152),
('new_idx', 120),
('sales_feb', 108),
('days', 104),
('months', 104),
('prices', 104),
('massachusetts_labor', 103),
('cols', 88),
('rows', 88),
('sales_cols', 88),
('count_by_class', 80),
('np', 72),
('pd', 72),
('plt', 72),
('USA_edition_grouped', 56),
('by_class', 56),
('by_class_sub', 56),
('by_company', 56),
('by_day', 56),
('by_mult', 56),
('by_sex', 56),
('by_sex_class', 56),
('by_year_region', 56),
('country_grouped', 56),
('france_grps', 56),
('life_by_region', 56),
('medals_by_gender', 56),
('regional', 56),
('splitting', 56),
('avg', 32),
('group_name', 28),
('x', 28),
('y', 28),
('NaN', 24)]
|
Certificate